[앞으로의 진도]
gpt → gpt API 프로그램으로 챗봇
엑셀작업 (산점도, 히스토그램 - 기술통계, 피벗테이블) → 파이썬 기술통계 (오늘 진도)
SQL (질의언어, 조인구문 중요), 파워 BI 시각화
파이썬 기초문법 (pandas 기초 문법)
- 서버에 있는 자료 (SQL)를 불러와서 자료분석 (혼자 / 여러사람 - 화면설계도 해야함 화면이 웹상 또는 로컬인지 고민해야함) 파일참고: 2. 파이썬에서 mysql 자료 조회.ipynb
- 칸아카데미 통계 자료 좋다 - 통계쪽 갈 사람들은 확인하기
https://ko.khanacademy.org/math/statistics-probability/analyzing-categorical-data
Khan Academy
ko.khanacademy.org
- 파이썬은 범주형인지 숫자형인지 따지는 경우가 많다.
- 추론하는데 있어서 통계와 시각화는 다르다. 데이터 시각화만 보고도 어느정도 추론할 수 있어야 하지 않냐라는 것이 요즘 트렌드이다.
오늘 배운 추론통계 분석
분석하고자 하는 문제를 정의하고, 귀무가설(H0)과 대립가설(H1)을 설정한다.
1) 정규성 검증 - 데이터가 정규분포를 따르는지 확인한다 (시각적방법 - 히스토그램, Q-Q플롯, 통계적방법 - Shapiro-Wilk 검정, Kolmogorov-Smirnov 검정)
2) 비모수, 모수 검정 - 정규성을 만족하면 모수 검정(t-검정, ANOVA)을 선택한다. 정규성을 만족하지 않으면 비모수 검정(Mann-Whitney U 검정)을 선택한다.
3) 귀무가설, 대립가설 검증
4) 정규분포일 때 검정 통계량, 정규분포가 아닐 때 검정 통계량 - p-value를 검토하여 귀무가설을 수용할지 기각할지를 결정한다.
5) 상관계수를 이용한 검정통계 - 필요에 따라 상관계수를 계산하고 변수 간 관계를 분석한다.
데이터분석에는 질적분석과 양적분석이 있다.

- 사용자가 입력한 문자에 대해서 분석하는 방법 - 질적분석
- 숫자데이터만 가지고 분석하는 방법 - 양적분석
ex. 학생들이 좋아하는 과일을 조사했다"라고 한다면, 과일 종류(사과, 바나나, 포도 등)는 범주형 데이터이고, 각 과일을 좋아하는 학생의 수는 수치형 데이터이다.
수치형 데이터는 숫자로 사칙연산이 가능하기 때문에, 통계적 분석/회귀 분석/시계열 데이터 같은 분석을 하고, 범주형 데이터는 데이터를 카테고리화 할 수 있어서 분류 작업/빈도 분석/의사결정 나무 모델 분석을 한다. 대부분의 데이터 분석 프로젝트에서는 범주형, 수치형 혼합해서 사용한다. 실제 데이터 세트에는 다양한 유형의 데이터가 공존하여, 각각의 특성을 이해하고 분석해야 좋은 결론을 도출할 수 있다.
연구논문에서는 질적분석, 양적분석 방법론이 다르다. 질적분석은 내가 말한 말이 어떤 범주에 있는지, 같은 시기에 나오면 같은 카테고리일 것이다라고 하는 것이다. 연구논문 쓰는 프로그램이 따로 있다.(유료) 우리가 파이썬과 같은 소프트웨어에서는 오브젝트형, 카테고리형으로 나눠서 한다. 범주형자료는 문자자료를 의미한다. 딕셔너리 구조에 따라 ‘성별’이 키가 된다. 외부데이터 불러올 때 키와 벨류값이 구분되어있으면 데이터분석에 용이하다.
베르누이 분포 - 머신러닝과 딥러닝에 사용된다. 확률적으로 어디에 가까운지 판별. 시그모이드만 쓰면 베르누이 분포 공식이 제공된다.
내가 가려는 분야가 수학/연구소라면 반드시 통계적 부분에 대해 알고가야한다. 프로그램 만드는 것에 집중한다면 수학 몰라도 문제없다.
요즘 경마에 관련된 경진대회가 많이 나오고 있다. GitHub에서 경마 검색. 경진대회 나갔던 자료 확인했다.


EDA 파트


산지에 따른 순위값을 확인했다. 두 데이터간에 연관성이 없어야한다. 통계방법론이 들어가있다.
귀무가설이 “두개는 연관이 없다” H0 가설이라고 해서 두 데이터 간에 연관이 있는지 없는지 확인하는 것이다. 나중에 다중공정선으로도 해야한다. 지금 이 단계에서는 연관성을 확인한다.
P-Value값이 0.05보다 작으면 귀무가설을 기각하게 되어있다. 5%정도는 다를 수도 있다고 생각한다.
카이제곱검증을 많이 사용한다. 명목형(범주형) 데이터에서 변수들 간의 관계나 독립성을 검정할 때 주로 사용한다.

P-Value 수학자들이 0.05라고 하지만 꼭 그럴필요는 없다.
T검정(분산값을 알고 있을 때)과 Z검정(모를 때)

그래서 데이터 분석할 때 귀무가설, 대립가설을 세우고 여러 검증을 거친다.



출처: https://github.com/mjs1995/Contest_Horse
GitHub - mjs1995/Contest_Horse: 경진대회_경마분석
경진대회_경마분석. Contribute to mjs1995/Contest_Horse development by creating an account on GitHub.
github.com
이 분석은 자세하지 못해 아쉬운 부분은 있다. 통계분석은 이것보다 훨씬 더 자세히 해야한다.
그래서 결국은 데이터분석 기법과 통계 기법 모두 다 해야한다.
건강보험심사평가원 자료 - 파이썬을 활용한 데이터 AI분석사례


교차분석

예제) 한 보험 회사에서 고객들의 평균보험료는 200,000원이고 표준편차는 100,000원이다. 최근에 추가판매 캠페인 등을 통하여 이 보험회사는 고객들의 평균보험료가 높아졌을 것이라고 판단했다. 이를 알아보기 위하여 총 100명의 고객을 추출하여 표본평균 값을 계산해본 결과 220,000원이 나왔다. 통계적으로 유의미한지 알아보자.
→ 가설은 H0는 200000, H1 > 200000이며, 검증통계량의 관측값은 2이다. P값은 0.023이다. 따라서 유의수준 0.05에서 통계적으로 유의하다고 할 수 있다.
교재 파이썬기반의 AI를 위한 기초수학, 확률 및 통계 14장 통계적 추론 읽어야함. 중요한 부분.
drinks.csv 파이썬 실습
출처:https://github.com/yoonkt200/python-data-analysis/tree/master
GitHub - yoonkt200/python-data-analysis: <이것이 데이터 분석이다 - 파이썬 편, 한빛미디어>의 예제입니다.
<이것이 데이터 분석이다 - 파이썬 편, 한빛미디어>의 예제입니다. 독자 여러분의 의견을 수렴하여 상시 업데이트 진행중입니다. - yoonkt200/python-data-analysis
github.com

→ 파일 경로 잘 설정해주기. 처음에 경로 복붙하면 \으로 되어있으니까 /로 바꾸고 csv파일명까지 입력해준다.


→ 데이터 맨 윗줄 10줄 출력

→ 기술통계 확인하기

→ 상관계수 행렬(correlation matrix)을 출력한다.








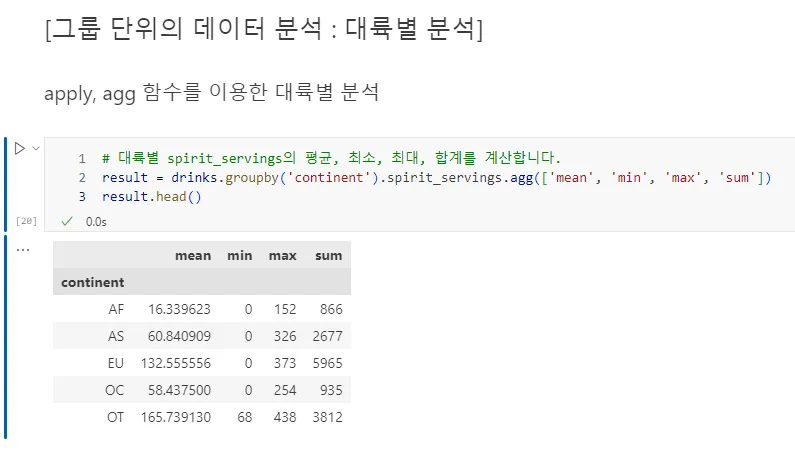






위의 예제코드에서 matplotlib의 각종 디자인 기능을 찾아봅시다.
- 첫 번째 그래프에서 4개의 통계 종류를 나타내는 디자인 기능이 담긴 코드가 어떤 코드인지 찾아보고 실행해 보세요.
- 두 번째와 세 번째 그래프에서, 하나의 막대만 다르게 색상을 변경하는 코드가 어떤 코드인지 찾아보세요. 그리고 막대를 녹색으로 바꿔보세요.
- 두 번재 그래프에서 점선을 표현하는 부분의 코드를 찾아보세요. 그리고 점선의 위치도 변경해 봅니다.


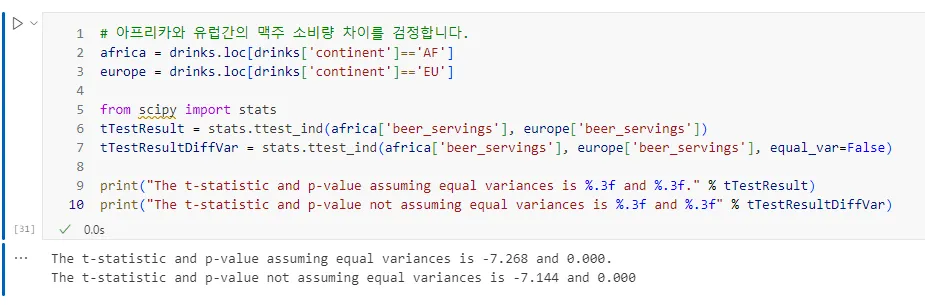
아래 결과값 가지고 지피티한테 해설해달라고 하기.
The t-statistic and p-value assuming equal variances is -7.268 and 0.000.
The t-statistic and p-value not assuming equal variances is -7.144 and 0.000.

등분산(equal variance)이란 두 개 이상의 집단이 가지는 데이터의 분산(variances)이 서로 동일하다고 가정하는 것을 의미한다. 분산은 데이터가 평균값에서 얼마나 떨어져 분포되어 있는지를 나타내는 척도이다. 두 집단이 있다고 할때, 이 두 집단의 분산이 같다고 가정하는 것이 등분산 가정이다. 반대로, 이 두 집단의 분산이 다르다면 이분산(unequal variance)이라고 한다. 통계검정에서 등분산 가정 여부는 t-검정 같은 분석 방법에서 중요한 역할을 한다. 만약 등분산을 가정할 수 있다면 t-검정의 계산 방식이 간단해지고 신뢰도가 높아지지만, 등분산을 가정하기 어렵다면 다른 공식을 사용하여 결과를 계산하게 된다.
P값이란? '이 차이가 우연히 발생할 확률'이다.
P값이 0.05보다 작으면? 우리가 관찰한 차이가 우연히 일어날 확률이 5%미만이라는 뜻으로, 진짜 차이로 볼 수 있다.
따라서, 아프리카와 유럽의 맥주 소비량 차이는 우연이 아닌, 실제로 차이라고 결론내릴 수 있다.


정규성 검증
추론통계의 순서를 알아보고, 정규성 검증은 어떻게 하는 지 확인했다.

시각적인 방법으로 택하면 데이터가 어디에 쏠려있는지 눈으로 확인할 수 있다.

데이터셋을 가지고 작업을 해서 불필요한 강수량이 0인 것은 삭제한다. 전체데이터의 많은 부분을 차지하고 있는 0값이다. 히스토그램을 보고 비가 온 날 분포도를 봐야한다.

히스토그램을 보고 일강수량이 50에서 80까지 범주값을 줘서 묶어버리기도 한다.
구조방정식을 이용해서 Y값에 영향을 주는 X값을 후보로 약300개까지도 한다. 제일 큰 문제는 나는 요인분석을 하기 위해서 Y결과값에 영향주는 요인값이 너무 많기 때문에 매개 변수를 두고 요인값들이 타당한 값인지 보는 것이 구조방정식 방법이다. 정규분포를 따른다는 가정하에. 정규성 검증을 먼저 한다. 데이터 정규성 여부를 확인한다.
왜도는 히스토그램의 방법 중 하나이다. 데이터 값이 너무 커서 데이터 정규성이 안나오면 로그를 써서 본다.(로그변환) 0에서 1사이에 가두거나, 로그값을 어떻게 처리하는지에 따라서
표준화, 정규화는 데이터를 일정한 값에 가둬버린다고 보면된다. 데이터값을 무한대로 주는게 아니라 일정한 사이즈로 줄여버린다는 것이다.
Bank 데이터 추론통계 (데이터 출처: 캐글)
연구 질문과 가설은 다른 것이다.

문제정의를 위해서는 변수를 분석해야한다.
df.info() 에서 데이터셋에 대한 설명을 GPT한테 물어본다.

데이터 변수 설명은 꼭 필요하다. 마지막 Y값에는 나이에 따라서 Y값의 변화가 있는지, 직업에 따라 변화가 있는가.

이 변수를 설명한 뒤에 GPT에 가설을 생성해달라고 해본다.
“Y값에 따른 귀무, 대립 가설 설정”

“Y값을 기준으로 한 연구질문”

아래 질문은 GPT로 생성한 것이다.

Y값이 있을 때, 쓸 수 있는 X값은 뭘까?를 확인하려고 하는 것이다.


파이썬 기초통계
파이썬은 활용도가 더 중요함으로 기초문법이 사용될 수 있는 활용문법을 같이 학습해야한다.
| 제목 | 링크 |
| 위키독스, 10. 리스트의 이해 ~ 19. for 반복문까지 |
https://wikidocs.net/16036 ~ https://wikidocs.net/16045 |
| 유튜브 동영상강의 포함된 자료는 02. 파이썬 변수 ~ 09. 파이썬 함수 |
https://wikidocs.net/78551 ~ |
| 05. 문자열부터 ~ 12장. 반복문까지 | https://wikidocs.net/65710 ~ |
| 위의 문법을 실전에서 어떻게 사용하는가 GPT에게 물어보기 | 파이썬 리스트, 딕셔너리 활용 EDA 파이썬 for 활용 EDA 샘플 파이썬 정규표현식 활용 실전데이터 샘플 파이썬 자료형 및 for, if가 들어간 텍스트 번역 및 텍스트 음성 출력 샘플 파이썬에서 노트북으로 들어오는 음성을 다양한 언어로 번역하는 코드최대한 쉽게 작성 하고 최대한 설명 자세하게함수없이 |
통계
| 주제 | 링크 | GPT에게 |
| 범주형 자료 분석하기 | https://ko.khanacademy.org/math/statistics-probability/analyzing-categorical-data | 파이썬 범주형 자료 분석 샘플 및 인사이트 |
| 양적 (숫자) 자료 그래프로 나타내기 (히스토그램등) | https://ko.khanacademy.org/math/statistics-probability/displaying-describing-data | 파이썬 양적 자료 그래프 샘플 및 인사이트 |
| 양적자료의 요약 (평균, 중앙값등 기술통계) | https://ko.khanacademy.org/math/statistics-probability/summarizing-quantitative-data | 파이썬 양적 자료 요약 샘플 및 인사이트 |
| 자료분포모델링 (백분위수, 상대도수) | https://ko.khanacademy.org/math/statistics-probability/modeling-distributions-of-data | gpt에게) 파이썬 자료분포 모델링(백분위수, 상대도수 포함) 및 인사이트 , 단 판매분석으로 |
| gpt에게, gpt코드에서 read한 sales_data를 생성하게 함) sales_data.csv 생성 | ||
| 이변량 수적 자료 알아보기 (산점도등) | https://ko.khanacademy.org/math/statistics-probability/describing-relationships-quantitative-data | 핀테크 자료를 이용하여 모델링 없이 최대한 많은 인사이트 도출파이썬 이변량 수적 자료 알아보기 (산점도등) |
| 물류 자료를 이용하여 모델링 없이 최대한 많은 인사이트 도출파이썬 이변량 수적 자료 알아보기 (산점도등) | ||
| 연구설계 | https://ko.khanacademy.org/math/statistics-probability/designing-studies |


그리고 인덱스, 어려운 개념이기는 하다.

전체데이터에서 훈련데이터를 뽑을 건데, 이거 만드는게 생각보다 되게 어렵다. Y값만 보는게 아니라 결혼여부도 봐야하고, 다른 요인도 봐야해서 샘플데이터 추출도 그렇게 해야해서 되게 힘들다. 무작위 추출이 있다. 아니면 계층별에 맞춰서 층화추출법도 있다.


총 385개 빼낼 것이다.

sample = df.sample(n=sample_size) 줄 넣으면 실행할 때마다 랜덤데이터가 달라진다.
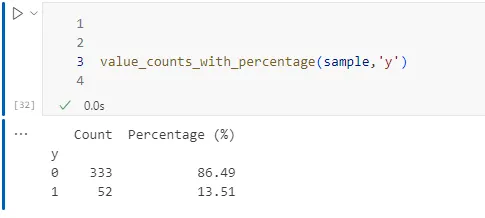
count, percentage 랜덤 데이터 달라지면 이 수치도 달라진다.
sklearn (사이클 런)모듈은 데이터 나눠진다. 머신러닝만 하는 전문적인 모듈이다. 이미지 분석을 전문적으로 했던 것이다. 층화추출이라는 것 자체가 385개를 뽑아주는데, 이 데이터를 가지고 작업을 할 때 train데이터를 나눠준다.

분류기법 쓰는 사람들이 random_state=42 안써서 무너지는 경우가 있다.
이 작업의 전제는 데이터값에서 모든 숫자변수는 분석할 대상이라는 전제조건이다.
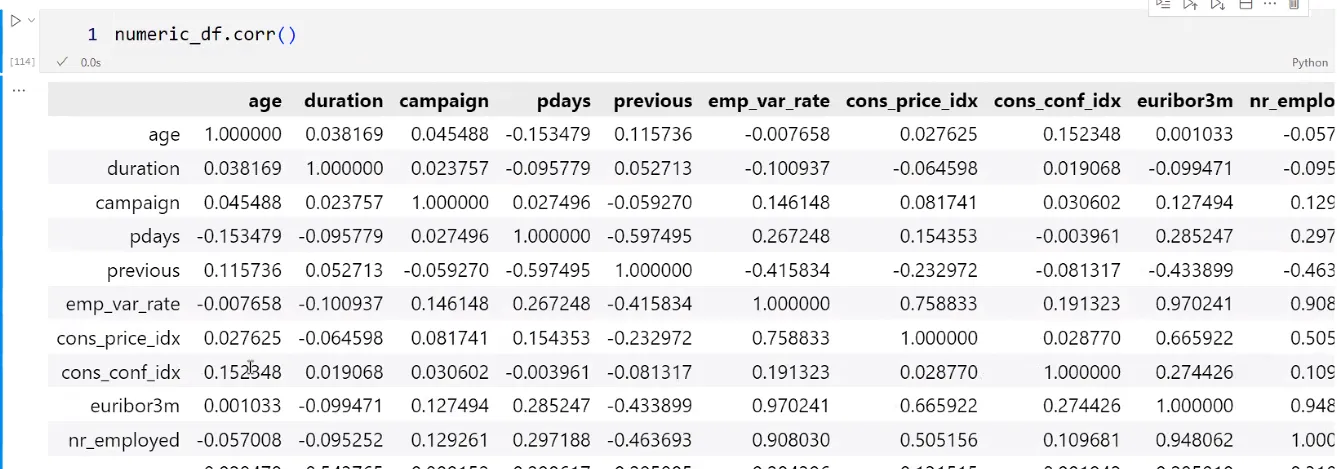
상관계수가 나온다.
Y값에 대한 상관계수를 구하려고 한다.

'커리어노트 📈 > KPMG 교육' 카테고리의 다른 글
| 인공지능과 생성형 AI (2) Gemini API, 멀티턴, temperature (1) | 2024.12.05 |
|---|---|
| 인공지능과 생성형 AI (1) PPT 보고서 (2) | 2024.12.05 |
| 기초 통계 및 경영 통계 (2) 파이썬 (0) | 2024.12.03 |
| 기초 통계 및 경영 통계 (1) 파이썬 (1) | 2024.12.02 |
| Project 기획 및 관리 (6) 고객 군집별 구매력 예측, 엑셀 시트 하나로 합치기 (1) | 2024.12.02 |



