뉴스기사는 중요하게 쓰일 수 있다. 법제가 포함되어있거나, 식품같은 경우는 식약처 표준이 바뀐것도 기사에 뜬다. 각각의 카테고리가 있다. 그런 자료들을 요약해서 카드 뉴스를 만들 수도 있다. 바뀐 법령이 나오면 요약본이 필요하다. 기존의 정책과 어떤게 바뀌었고, 어떤게 남아있는지 (숫자가 아님)를 알아야 해서 요약본이 중요하다. 스페이스 하나도 다른 단어로 인지한다. 오픈 AI의 단어셋이 있어서 가능하지만, 예전에는 이거는 상상도 못한 일이었다. 하지만 지금도 고전적인 방식으로 문장 분석을 많이 한다. 고전적인 방식은 안녕, 나는, 산책 모두 형태소로 쪼갠다. 구글 ‘KONLPY 파이썬’ 검색, 형태소 단위로 글자를 쪼갤 수 있도록 모든 단어를 등록해놓은 패키지이다. 카이스트에서 이걸 했다. 일일이 단어사전을 만들어야 한다.
LLM작업의 근간. 언어의 형태소와 단어의 조합이라는 베이스가 깔려있어야 한다. 우리는 프로그래머들한테 이렇게 해달라고 부탁하는 사람들이다. 기획테이블에서 코드를 그래도 조금 알아줘야한다. “데이터셋에 불필요한 자료나 패턴이 이렇게 되어있어서 제거해주세요.” 그래서 우리는 데이터셋을 잘봐야한다. CSV 인코딩은 CSV 파일이 저장되는 방식, 즉 텍스트 데이터를 컴퓨터가 이해할 수 있도록 특정 형식으로 변환하는 방식을 말한다. CSV 파일은 일반적으로 텍스트 데이터로 구성되어 있기 때문에 파일을 열고 읽을 때 어떤 인코딩 방식을 사용했는지에 따라 올바르게 보일 수도 있고 깨져 보일 수도 있다.

예를 들어, CSV 파일을 생성하거나 열 때 프로그램에 따라 인코딩을 설정해야 할 때가 있다. 만약 인코딩이 맞지 않으면 한글이나 특수 문자가 깨져서 "����" 같은 식으로 보일 수 있다. 따라서 CSV 파일을 읽거나 쓸 때 올바른 인코딩을 지정하는 것이 중요하다.

카페매출 데이터 분석
지피티에 DB 구축을 하고 Tkinter를 이용해서 조회 서비스 구축하는 파이썬 코드를 짜달라고 한다.

DB쪽은 너무 고전이라 GPT가 잘 만들어준다.


우리가 추후에 지피티 API를 만들면 회사에서도 이러한 것들을 다 쓸 수 있다. 지피티만 구축해도 이런걸 쓸 수 있다. 데이터 셋을 넣고 분석해달라고 할 수 있다. 사람들이 저런 단어(’파생변수’)를 못넣으니까, 데이터만 넣고 돌리면 그냥 나온다. 데이터분석을 하고싶고, 봐야하는데 모른다면 그냥 자동화를 시켜버린다. 데이터를 올리는 순간 데이터 셋에서 뭔가를 할 수 있게끔 한다.
지피티에 질문예시


날씨데이터랑 결합할 수도 있다. 새로운 변수들을 만든다.
답변을 확인한다.


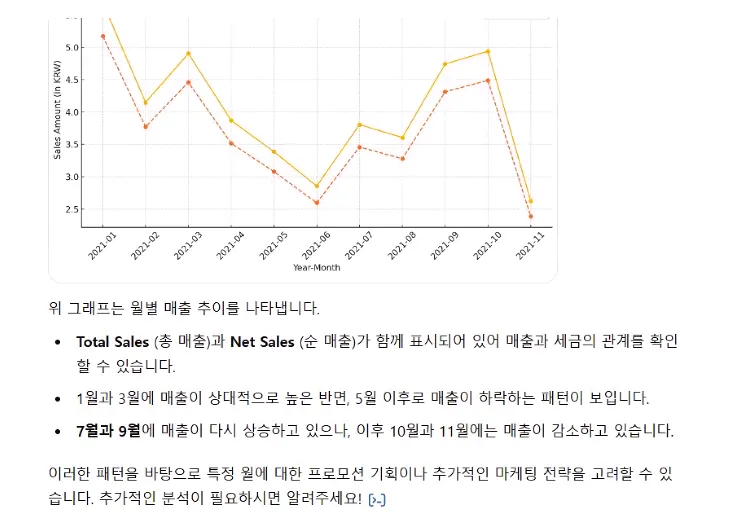
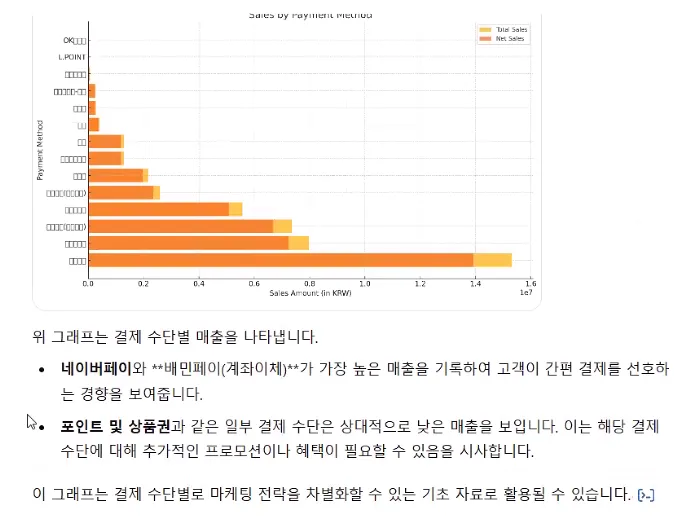
이제 사람보다 얘가 낫다…
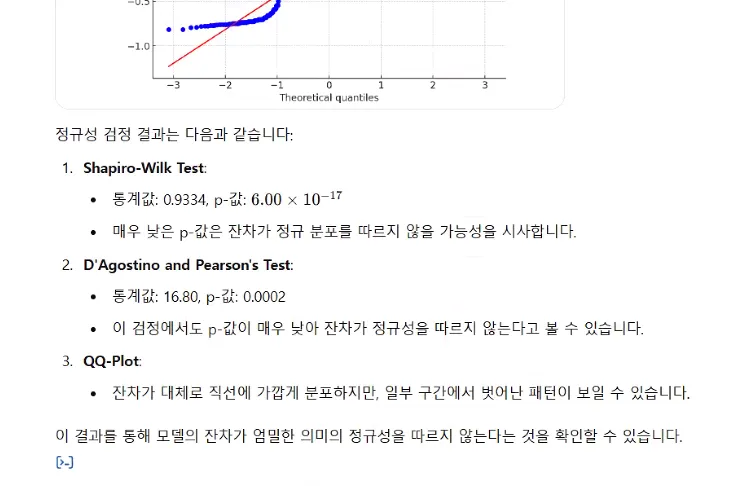
정규성 분석까지 해준다.
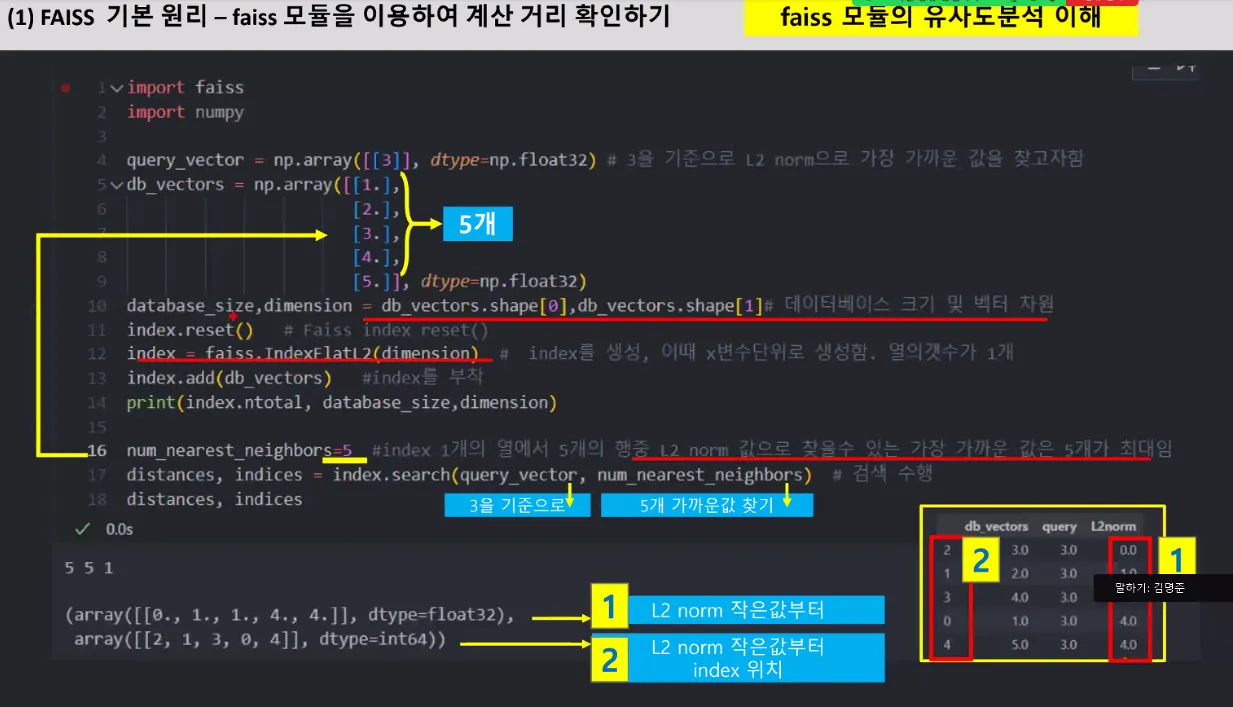
L2 Norm 거리값 계산해서 유사도 분석해줄 수 있음
https://hwanii-with.tistory.com/58
[이론 및 파이썬] L1 Norm과 L2 Norm
글을 시작하며.. 글의 순서 Norm 이란? L1 Norm L2 Norm L1 Norm과 L2 Norm의 차이 Norm이란? Norm은 크기의 일반화로 벡터의 크기(혹은 길이)를 측정하는 방법입니다. 두 벡터 사이의 거리를 측정하는 방법이
hwanii-with.tistory.com
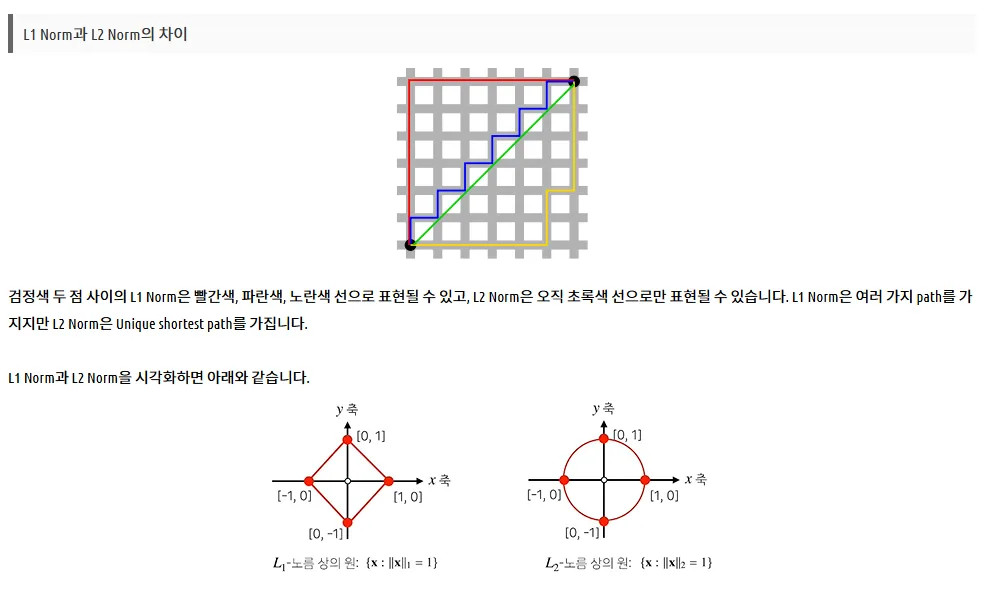
이거를 구현해놓은 함수가 있다. L2 norm
Faiss (Facebook AI Similarity Search) - 매우 빠르고 효율적인 벡터 검색과 유사성 검색을 수행하기 위해 설계된 도구입니다. 페이스북에서 개발함. 엄청 많은 벡터에서 작업을 한다.
텐서플로우는 구글꺼
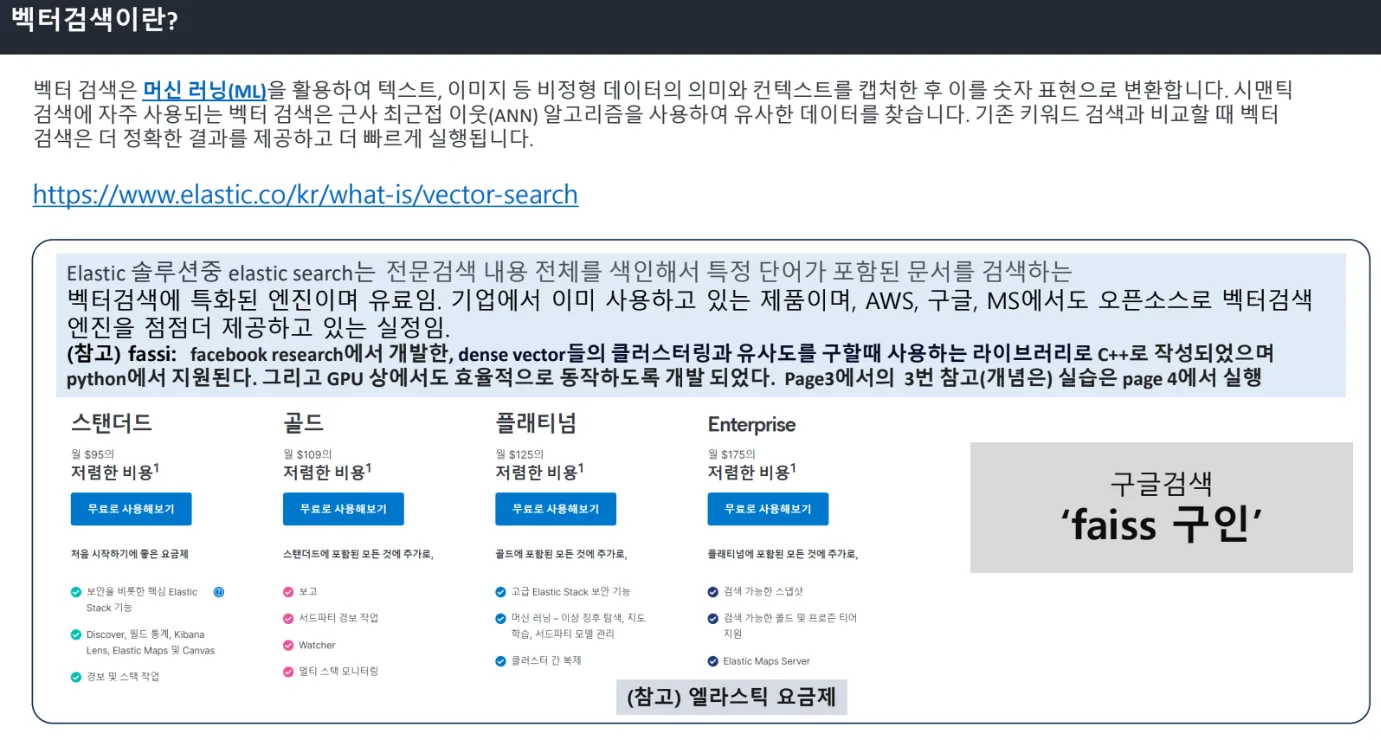
기존의 키워드 검색보다 빠르다. 인덱스 색인을 찾기 위한 방법론은 차근차근 찾는 것보다는 해쉬태그를 찾는게 빠르다.
엘라스틱은 플랫폼 이름이고, 엘라스틱이라는 솔루션이 있는데 대기업들이 썼었다. 엘라스틱 솔루션 중에서 엘라스틱 서치가 벡터검색하는 전문 솔루션이다. 인터넷에 있는 자료들 벡터단위로 해서 빨리 검색하는 것이다. 회사 평판검색해야할 때, 일반적인 검색속도로 할 수 없어서 벡터단위로 검색해서 빠른 검색하는 것이다. 라이센스가 필요한 플랫폼이라서 엘라스틱과 관련된 라이센스를 취득해줘야한다. 라이센스가 40만원정도 한다. 플랫폼에 대한 비용도 몇백 든다. 취급하는 회사도 공식 인증된 회사만 쓸 수 있다. 아무나 사용할 수 없다. 폐쇄적인 망에서만 사용할 수 있었다. 지금은 인공신경망이 개발되면서 오픈 AI에서 벡터단위로 데이터를 만들어 놓으니까, 벡터검색 DB가 나온 것이다.
Dense Vector (밀집 벡터): 머신 러닝과 딥러닝에서 자주 사용되는 데이터 표현 방식으로, 모든 요소가 연속적인 값(실수)을 가지는 벡터를 의미한다. 주로 특징(feature)을 나타내기 위해 사용되며, 특히 자연어 처리(NLP), 컴퓨터 비전(CV), 추천 시스템 등 다양한 분야에서 사용된다. 이 벡터는 보통 딥러닝 모델을 학습시켜 얻거나, 사전에 훈련된 임베딩(embedding) 모델을 통해 계산된다.
정형데이터는 결측치가 문제다. 말, 빅데이터 텍스트는 비어있는 데이터가 많다보니까 빈데이터를 빼서 데이터값을 잘 쪼개서 다시 붙일 수 있을까?가 매우 큰 고민이다. 그래서 수학이 중요하다.
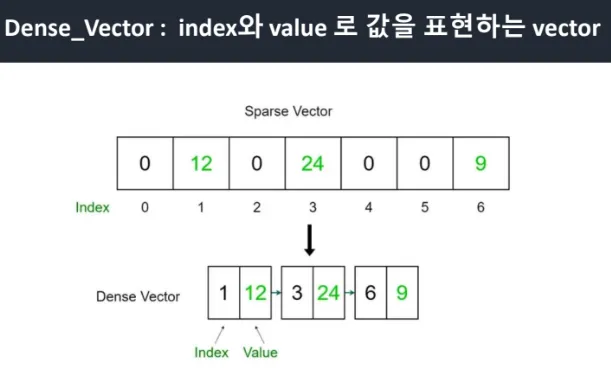
그래서 위에 사진처럼 있는 데이터만 표시하자고 해서 만들어진 거다. 사이에는 링크라는 별도의 개념이 필요하다. 설계 구조자체가 아예 다르다. 밀집 벡터라는 것을 사용함으로써 공간 자체를 줄일 수 있고, 처리 속도도 빠르게 할 수 있다. 이런 것까지는 아직 고민하지 않아도 된다. 벡터DB라는 용어만 알고가도 괜찮다. 벡터DB를 지원하는 프로그램이 예전보다 많아졌다.
기존 데이터베이스는 정확한 검색과 구조적 데이터에 적합합니다. 데이터가 테이블 형태로 명확히 정리되어 있고, 값을 정확히 매칭하거나 조건을 필터링하는 데 강합니다. "ID가 123인 고객의 이름은 무엇인가?"와 같은 정확한 값을 찾는 질문에 적합합니다.
벡터 데이터베이스는 유사성 기반 검색과 비정형 데이터에 적합합니다. 벡터 형태로 데이터를 저장하고, 유사한 것들을 찾는 데 사용됩니다. 이미지를 검색하거나, 문서의 의미를 비교하거나, 추천 시스템을 구현하는 데 뛰어난 성능을 발휘합니다. "이 사진과 비슷한 다른 사진은 무엇인가?"와 같은 유사성을 찾는 질문에 적합합니다.

CSV 로더기 안에 들어가보면 수많은 로더기를 들고서 가지고 들어오는 거다. 그래서 단순한 건 아니다. 로더기 안에서 객체들이 있다고 보면 된다.
여기서부터 Q&A 입력하는거 프로젝트 하라고 했는데 못함…
'커리어노트 📈 > KPMG 교육' 카테고리의 다른 글
| 디지털 이노베이션 및 빅테크 AI Business 전략 (2) 오픈 AI 임베딩, RAG, 파싱, requests 모듈, 웹데이터 구조 (4) | 2024.12.06 |
|---|---|
| 인공지능과 생성형 AI (7) ChatGPT API (0) | 2024.12.05 |
| 인공지능과 생성형 AI (6) 랭체인, LLM, LCEL (6) | 2024.12.05 |
| 인공지능과 생성형 AI (5) 가상환경 셋팅, 랭체인 로더기 (3) | 2024.12.05 |
| 인공지능과 생성형 AI (4) Tkinter 패키지, GUI 구현, 파이썬 (함수 / 패키지 / 모듈) (3) | 2024.12.05 |



