Word Cloud - 텍스트 카운트 개수를 세서 시각화함, 워드 클라우드는 맨 앞장에

LLM (Large Language Model)은 매우 큰 규모의 파라미터(매개변수)와 데이터로 훈련된 인공지능 모델로, 인간 언어를 이해하고 생성할 수 있는 능력을 가지고 있다. 이러한 모델들은 특히 자연어 처리(NLP, Natural Language Processing) 작업에 뛰어난 성능을 발휘하며, 언어 생성, 번역, 요약, 질문 응답 등 다양한 언어 관련 작업을 수행할 수 있다. 예를 들면 GPT.
블로그 A, 블로그 B를 분석했을 때 워드 빈도수가 다르다. 블로그를 늘릴 수록 0이 많은 테이블이 된다. 키워드 단위로 쪼개면 카운트수가 너무 많아져서 컴퓨터가 처리하기엔 크기가 너무 클 수 있다. 어떻게 하면 크기를 줄일 수 있을까라는 고민을 한다. Term 단위의 Frequency를 다루겠다고 함. 역빈도수라는 IDF를 이용해서 누구에게나 다 나오는 단어는 필요없다. 다른데 안나오는 특수한 데이터셋만 보겠다는 것이다. 내가 A부터 Z까지 장바구니를 분석한 결과 모두에게 생수가 있다면 이건 분석 대상이 안된다. 그런데 이 장바구니에만 있는 물건을 분석하는 것이 예측분류 마케팅에 해당한다.
트렌드 분석에 있어서 키워드 하나 분석하는 것이 말이 쉬울 뿐이지 여전히 지금까지도 아직도 위의 방법으로 분석하는 것이 기본이다. 비용이 천 이천 금방 들어간다. 엄청 비싸다.
자연어처리 - 사람이 말하는 것과 같은 글을 분석할 수 있는 것. 긍정, 부정, 중립을 분석할 수 있다. 사람이 만들어서 넣은 것이다. 우리나라 말을 띄어쓰기 안해도 알아먹고, ‘헐 대박’처럼 긍정인지 부정인지 뒷말까지 들어봐야하는 경우가 많아서 분석이 쉽지 않다는 특징이 있다.
비교분석 - 건강관련해서 많이 있다. 오보에 대한 정정들이 많이 나오고 있다. 이런 것도 오보 분석을 해서 학계에서 새로운 것들이 나오기 때문에 비교분석 할 수 있다.
네트워크 분석 - 관계도망, 길이와 크기에 따라서 관련도 분석
구현보다 중요한게 ‘기대효과’ 공공기관 공모전은 그런것이 중요하다. 거하게 써도 된다. 아이디어는 잘 구현하는 팀들이 많지만 기대효과가 어떻냐고 중요하다. 공모전 상탄거 보여주겠다.
IT가 세상을 바꾸고 있다는 것을 느끼고 있다. 속도가 너무 많이 빠르다. 인공지능 논의가 꾸준히 되다가 버트라는 모델이 나오고 응용되서 gpt가 되었다. 버트는 사실에 의거해서 만들어내는 알고리즘이고, gpt는 창의적인 것에 쓰였다가 오픈 AI라는 기업이 나왔다. 이 기업은 강화학습이라고 해서 스스로 뭔가를 해보고 다시 해보는 강화학습을 오래전부터 했었고, 큐러닝도 여기서 나온 거다. gpt 모델을 오픈할게 라고 해서 나온거다. gpt가 갑자기 나온 것이 아니었다. 히스토리를 좀 알아야한다. 2019년 이전에 우리나라는 IT가 다운이었다. 이때는 외국은 데이터분석과 인공지능이 살아난 때라서 이 데이터가 격차가 벌어지면 너무 많이 벌어진다. 데이터수집하고 분석하고를 반복하기 때문에 데이터를 가지고 있고 분석하는 팀은 성장할 수 밖에 없는 구조이다. 우리나라는 데이터를 손 놓았던 시기에 외국에서 한참 데이터 인공지능이 살아났던 것이다. 그래서 우리나라는 너무 많이 늦어버렸다. 국가 주도 하에 데이터 사업을 엄청 많이 벌이고 있다. 그 일환으로서 빅카인즈도 언론재단에서 만든 것이다.
예를 들어서 선박 빅데이터를 제공하는 페이지가 있다. 외국에서는 이 데이터 거래 마켓이 생긴지 오래되었다. 보건의료빅데이터개방시스템이 있다. 서울시 빅데이터 캠퍼스가 있고, 세금으로 만든 데이터이다. 이런 데이터들이 한가지 포털에 모여있는게 공공데이터포털이다. API 라는 것은 실시간 데이터에 접근할 수 있는 것? 무료 유료 섞여있다. 빅카인즈는 기본적으로는 API를 공모전 참여자에 한해서 준다. 기사같은 정형데이터가 아닌 음악, 음성 이런 것들은 AI허브라는 사이트가 있다. AI허브라는 쪽에 들어가면 수많은 비정형데이터 세트가 있다. 예를 들어 노인 정신건강 영상 데이터세트도 있다. 여기는 데이터만 주는 게 아니라 이런 데이터를 갖고서 어떻게 개발을 했는지라던지, 어떤식으로 모델을 만들었는지를 다 주고 있다. 인공신경망 모델을 만들지 않아도 되기 까지 하다. 모델 하나 개발하는데 1억에서 5억 한다. 우리나라는 AI가 대기업 주도가 아니라 자동화를 시키지 못한 곳에서 자동화를 시키는 곳 어떤 사안에 대해서 그 사안에 잘알고 있는 숙련도가 있는 부분을 자동화 하는 것이다. 내가 갖고 있는 숙련도를 프로그램화 시키는 것이 AI다. 그런 숙련도를 프로그램화시키는 것이다. 숙련도가 없더라도 숙련화되어있는 사람처럼 프로세스를 할 수 있게 가이드를 해주는 것이다. 키오스크가 들어옴으로서 인력을 대체한다. 프로세스되서 자동화될 수 있는 직군들이 대체되는 것이다. 예술직군이 더 잘 살아남는다고 한다. 그 위에거를 해야한다.
우리나라가 IT 교육에 투자하는 이유는 자원이 없기 때문이다. 어린애들에게 IT 교육을 강조하는 이유는 창의력이 필요하기 때문이다. 어린이들에게 창의교육을 시켜야한다라고 했을 때 기대효과는? 국가가 원하는 답을 해줘야한다. IT를 통해서 할 수 있는 것이 창의교육이다. 기술이 아이디어를 다 표현할 수 있다라는 것이 창의력이다.
인공지능 전문기업 코난테크놀로지
자체개발 대규모 언어모델 'Konan LLM', 생성형 AI시대를 이끌어갑니다.
www.konantech.com
[AI, 데이터분석 관련 회사 플랫폼]
- 삼성 브라이틱스 AI
- LG CNS 커뮤니티
- 카카오 IF (기술 블로그, 컨퍼런스)
- 당근 기술 블로그
- 네이버 API, 카카오 API, MS API, IBM API, AWS API (API는 기술을 일정 비용 또는 무료로 사용할 수 있게 연결해주는 인터페이스임, 단 사전에 계정만들고 승인 받아야함)
- 기술자블로그 - 기술쪽으로 가고 싶은 사람들은 참고하기
기업 AI 활용은 대부분 기업을 통해서 한다. 학교랑 하는 것은 데이터만 주고 인사이트 받으면 좋구 이정도이다. AI활용 프로그램을 만드는 회사들을 통해서 자동화, AI 도입한다.
한국에서 취업한다면 AI 기획자 또는 대기업 (영어만 해도 AI 활용 사례 논문을 읽으면서 새로운 아이디어를 찾아주는 일이라도 할 수 있다), 외국으로 돌아간다면 수학 통계해서 포폴만들어서 재지원
내 포트폴리오 피드백 - 기술자 입장에서 보면 기술통계가 없고 너무 단순해서 2일만 배우면 되는 정도의 수준임, 경영자 입장에서 보면 차트 아래 인사이트가 없어서 부족한 리포트이다. PPT를 만들어서 인사이트, 왜 이거를 해야하는지에 대한 이야기를 해야한다. 캐글 많이 참고하자 특히 Overview가 엄청 길다는 것을 참고해라.
MS오피스 구독 서비스 하고 있는데, 여기서 클라우드의 장점이 업데이트다. 클라우드 공간에 접속해서 써라고 하는것이다. 프로그램을 공유한다. 자원을 공유한다. 기업들은 공유하는 것을 안좋아하는데도 불구하고 머신러닝, 딥러닝 이런거는 공유를 할 수 밖에 없다. 공유하는 서버를 어떤 것을 쓰는가하면 클라우드이다. 네이터 클라우드를 쓸건지, 구글 클라우드를 쓸건지 아마존의 클라우드를 쓸건지를 본다. 외국은 기술자 비용이 굉장히 세서 모든 것들을 기술자로 채울 수 없다. 그래서 아마존같은 서비스에 빌리는 것이 저렴해서 클라우드, 분석 시스템을 빌려서 쓴다. 클라우드는 내가 직접 시스템을 개발하지 않고, 회사에 접속해서 사용하는 것을 클라우드 시스템이라고 한다. 우리나라 대기업도 클라우드를 쓸 수 밖에 없는 쪽이 딥러닝, AI이다. 우리나라는 클라우드는 네이버를 밀어준다. 시스템을 잘 구축하는 사람들을 Cloud Engineer다. 클라우드 과정은 우리과정보다 쉽다. 우리 과정보다 훨씬 쉽다. 클라우드는 어렵지 않지만, 클라우드의 핵심은 보안이다. 보안이슈에 부딪힐 수 밖에 없다. 나중에 서비스 작업 프로젝트 할때 클라우드를 붙이는 것을 권장한다.
대형마트가 데이터분석을 안했던 이유는 안해도 잘되고 있었기 때문이다. 그런데 지금 온라인 주문으로 많이 넘어갔다. 시기나 주기별로 상품을 구매할 수 밖에 없는 제품들이 있다. 도루코가 구독서비스를 이용해서 잘 유지하고 있다. 충성고객들을 잘 가둬눠야 하는 것도 하나의 큰 과제이다. 요즘 OTT회사는 어떤가? 유아동 컨텐츠 사업이 정말 크다. 엘지 유플러스에서 컨텐츠를 가만히 앉아서 보는 친구들이랑 AI 서비스를 쓰면서 본 친구들이랑 다르다. 유투브처럼 보기만 하면 말이 어눌하고 나쁜 말을 배운다. 하지만 엘지 유플러스는 유아동 컨텐츠의 사업에 힘을 쏟고 있다. 이런 서비스는 파급효과가 있다. 컨텐츠 사업은 파생상품이 많다. 하나의 캐릭터, 컨텐츠 잘 만드면 산업 대비 10몇배씩 증가한다. 규제를 많이 하는편인데 게임은 규제의 대상이 아니라고 국가에서 말하고 있다. 게임의 문제가 아니라고 정의하고 있다. 그 이유는 게임이 고부가가치 사업이기 때문이다.
외국과 우리나라는 환경차이가 커서 데이터분석 사례를 바로 가져다가 쓰기가 어렵다. 인공지능 학자가 전세계에서 두나라만 해도 다 할 수 있다고 하는데 그게 남한과 북한이었다. 우리나라는 소비자 패턴이 없기 때문이다.
과기부 산하에 IT만 전문적으로 하는 공공기업의 데이터 플랫폼이다. 데이터셋도 많고, 무료로 볼 수 있는 온라인 강의도 있다. 소식지 및 보고서 - 빅데이터 우수사례집 -
“중소기업 빅데이터 분석·활용 지원사업 우수사례집”
2022년도에 했던 거라서 여전히 정형데이터에 있어서는 비슷하게 하고 있었고, 코난/빅재미 기업에서
예전 경영학에서부터 써왔던 연관분석을 사용한다.

두 제품을 매칭해서 팔면 좋다는 것을 분석.
지지도, 신뢰도, 향상도 → 예전 경영정보학임, 요즘은 추천시스템을 사용한다.
향상도 1이 넘으면 의미있는 것.
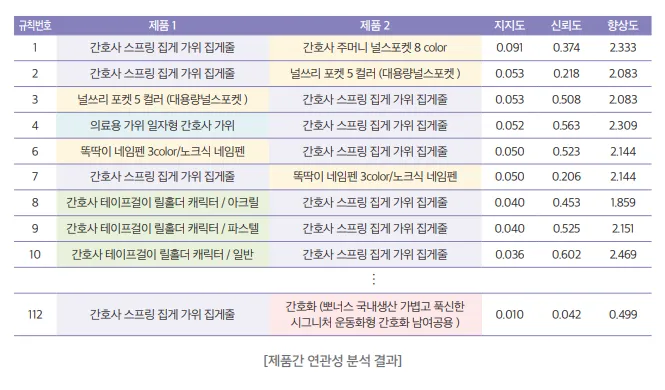
데이터 분석에서 중요한 것: 이 분석이 필요한 이유는 무엇인가. 연관분석을 시행해서 이걸 기반으로 추천시스템을 구축하였다.
느낀 점: 인공지능도 갑자기 나온게 아니라 옛날부터 말 나와서 지금 뜬거다. 하나의 기술에서 파생되는게 많다. 하나를 하고 경력을 쌓다가 파생된것을 이어서 갈수도있다. 왜냐면 다 연결이 되기 때문이다. 그래서 너무 미래를 고민하지 않아도된다. 하는걸로 그걸로 가지치기 하듯이 또 일이 있기 때문이다.
취업
채용 NLP Researcher / Engineer
LLM모델 사용하거나 공부한 경험이 있는사람, NLP 제품 개발 경험이 있는 사람 → 할 수 있다
AI관련 수상이나 논문 작성 경험 있는 사람
뚜껑열어보면 연봉 3500 주고 한다. 왜냐면 ‘이해’인거지 ‘구현’이 아니다.
Google Analytics는 GA이고, Performance Marketer (퍼포먼스 마케팅)공고들은 데이터 분석이라고 찾아도 되지만, 마케팅에 대한 이해필요하고 엑셀이나 피피티정도만 한다. GA 데이터분석이 주업무이다. 처음에는 연봉이 적을 수는 있으나 2-3년되면 중견들어갈 수 있다.
하다 못해, 기술영업은 제안서, 협약, 업계동향 가지고 네트워킹 참여해서 IT산업에 대한 전반적인 이해도가 좋아야 한다.
IT기획 - 플랫폼 및 클라우드 환경 SaaS 서비스 UI/UX 기획, 프론트/백엔드 서비스 기획, 고객 피드백을 바탕으로 신규 서비스 및 개선점 도출, QA 및 A/B테스트를 통한 개선점 도출, 시장리서치 및 트렌드 분석을 통한 방향성 수립, 포트폴리오 제출
- QA도 난이도가 있는 업무다. 데이터베이스를 잘해야한다.
MIS 안에서 이런 통계기법을 비즈니스에 쓰일 수 있다는 것으로 장바구니 분석으로 사용되고 있다.
연관성


장바구니 연관분석
비지도학습 - Y라는 값을 찾으려는게 아니라, 데이터 뿌리고, 데이터를 Segmentation하려는 것이다.
연관관계 분석
POS도 회사마다 다르다. 쿠팡에서 온라인 마켓을 노리지만 오프라인 마켓도 노린다. 온라인의 문제는 충성고객이다. 온라인 매장에서도 오프라인 관심도가 생겨서 POS에도 관심을 가지고 있다. 영수증 안에 커피 5개를 샀던 생수 10를 샀던 관심 없다. 영수증을 보면 커피, 생수, 면도, 고객넘버가 있으면 실제 프로그램에서는 한개에 같은 성격을 가지면 제품을 모두 한줄로 쓴다. 위에서 아래로 데이터가 보이지만 프로그램으로 돌릴때 문제는 데이터 형식이다.
지지도는 전체중에서 동시 출연 빈도수를 의미한다. 지지도 / 신뢰도
지지도가 높다는 건 모든 사람들이 많이 구입한다는 것을 의미한다.
신뢰도는 동시에 구매될 확률을 의미한다.
Lift - 1이 연관성 없음, 1보다 작으면 둘이 셋팅하면 마이너스 된다는 뜻이다.


1. 지지도 (Support)
지지도는 두 항목이 동시에 발생하는 빈도를 나타내는 비율입니다. 예를 들어, '담보'와 '소리'가 함께 구매된 경우의 비율을 나타냅니다. 계산식은 다음과 같습니다:
이미지에 있는 표에서, '담보'와 '소리'가 함께 구매된 거래 수는 20/50입니다. 즉, 전체 50건의 거래 중에서 20건에서 '담보'와 '소리'가 동시에 구매된 것입니다. 따라서 지지도는 0.4로 나타나 있습니다.
2. 신뢰도 (Confidence)
신뢰도는 한 항목이 발생했을 때 다른 항목이 발생할 확률을 의미합니다. 예를 들어, '담보'를 구매한 고객 중에서 '소리'도 구매한 고객의 비율을 나타냅니다. 이는 연관 규칙에서 "A가 발생했을 때 B도 발생할 확률"로 해석됩니다. 계산식은 다음과 같습니다:
이미지에 따르면, 담보를 구매한 고객이 30/50 (0.6)이고, '담보'와 '소리'를 동시에 구매한 고객이 20/50 (0.4)입니다. 이때 신뢰도는 0.4 / 0.6 = 0.67로 계산됩니다. 즉, '담보'를 구매한 고객의 67%는 '소리'도 구매했다는 것을 의미합니다.
요약:
지지도(Support): '담보'와 '소리'가 동시에 발생한 비율로, 여기서는 0.4 (20/50). 신뢰도(Confidence): '담보'를 구매한 고객 중에서 '소리'도 구매한 고객의 비율로, 여기서는 0.67 (67%).
이 두 지표는 연관 규칙 분석에서 중요한 요소로, 고객이 특정 아이템을 구매했을 때 다른 아이템을 구매할 가능성을 예측하는 데 사용됩니다.
장바구니 분석은 고전적인 방법이다. 데이터가 너무 많이 발생한다?
장바구니 아이템이 너무 많으면 빈공간이 너무 많고, 양은 많지만, 많은 양을 컴퓨터가 처리하지 못하게 되었다. 행렬분해와 같은 기술을 사용해야 한다. 그래서 유저 시스템, 유저 분석, 협업 필터링이 상위 기술이다.
'데이터 AI 인사이트 👩🏻💻 > KPMG 교육' 카테고리의 다른 글
| Project 기획 및 관리 (1) MySQL (0) | 2024.11.15 |
|---|---|
| Business AI 개론 및 IT 산업 혁신 (5) (12) | 2024.11.11 |
| Business AI 개론 및 IT 산업 혁신 (3) (5) | 2024.11.11 |
| Business AI 개론 및 IT 산업 혁신 (2) (0) | 2024.10.22 |
| Business AI 개론 및 IT 산업 혁신 (1) (0) | 2024.10.22 |



