K-Nearest Neighbors(KNN)는 거리 기반 학습 알고리즘으로, 새 데이터 포인트의 분류(Classification)나 회귀(Regression)를 위해 가장 가까운 K개의 데이터 포인트를 참고한다. 비지도 학습처럼 보일 수 있지만, 주로 지도 학습(Supervised Learning)에 속한다.
KNN은 학습 단계에서 모델을 생성하지 않고 데이터를 그대로 저장한다. 새로운 데이터 포인트를 분류하거나 값을 예측할 때, 기존 데이터를 기준으로 거리를 계산하여 가장 가까운 이웃 K개의 데이터를 참고한다. 이 이웃들의 다수결이나 평균을 바탕으로 결과를 예측한다.
KNN 작동 원리
KNN은 새로운 데이터 포인트가 주어졌을 때, 학습 데이터 중 가장 가까운 K개의 이웃을 찾아 이웃의 정보를 기반으로 결과를 예측한다. 이 과정은 크게 세 단계로 나뉜다.
1. 특징 공간에서 거리 계산
거리 계산은 새 데이터 포인트(테스트 데이터)와 학습 데이터(기존 데이터) 간의 유사성을 측정하기 위해 사용된다. 일반적으로 유클리디안 거리를 가장 많이 사용하지만, 데이터의 특성과 문제에 따라 다른 거리 계산 방법을 사용할 수도 있다.
- 유클리디안 거리는 두 점 사이의 직선 거리다. 수식은 다음과 같다:

- 맨해튼 거리는 축을 따라 이동한 거리로 계산한다:
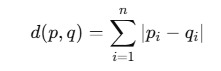
- 코사인 유사도는 두 벡터 간의 각도로 유사성을 계산하며, 1에 가까울수록 유사도가 높다:

2. K개의 이웃 선택
거리를 기준으로 학습 데이터 중 가장 가까운 K개의 이웃을 선택한다. 여기서 K는 하이퍼파라미터로, 사용자가 직접 설정한다. 가까운 이웃을 정렬한 뒤, 상위 K개의 데이터만 선택하면 된다.
3. 예측
- 분류(Classification): 선택된 K개의 이웃 중 가장 많은 빈도로 나타나는 클래스를 결과로 반환한다. 다수결 투표 방식이라고 보면 된다.
- 회귀(Regression): 선택된 K개의 이웃 값의 평균을 계산하여 결과로 반환한다.
K 값 설정
K는 KNN의 성능에 매우 큰 영향을 미치는 중요한 하이퍼파라미터다. 데이터를 기준으로 최적의 K값을 선택해야 한다.
1. K값이 너무 작을 때
- 모델이 과적합(Overfitting)될 가능성이 높다.
- K=1인 경우, 가장 가까운 하나의 데이터만 참조하므로 노이즈에 매우 민감해진다.
- 결과적으로 데이터의 전반적인 패턴보다 개별 데이터 포인트에 치중하게 된다.
2. K값이 너무 클 때
- 모델이 과소적합(Underfitting)될 가능성이 높다.
- K값이 커질수록 더 많은 이웃을 고려하기 때문에 국소적인 패턴이 무시되고 전체 데이터의 평균적인 결과로 수렴할 수 있다.
- K가 데이터 개수에 가까워지면 모든 데이터의 평균값을 반환하는 수준으로 단순해질 수 있다.
3. 적절한 K값 선택
적절한 K값은 데이터의 특성과 분포에 따라 달라진다. 일반적으로 K값은 다음과 같은 방법으로 설정한다:
- 홀수 사용: 분류 문제에서 클래스가 2개인 경우, 다수결 투표에서 동점이 되는 것을 방지하기 위해 K를 홀수로 설정한다.
- 교차 검증(Cross-Validation): 다양한 K값에 대해 교차 검증을 수행하여 최적의 K를 찾는다.
- K값의 범위: 데이터 크기의 √ n 을 기준으로 K값을 설정하는 것이 일반적이다. 예를 들어, 데이터 포인트가 100개라면 K=10 정도에서 시작해보는 것이 좋다.
4. K값 찾는 코드 예제
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
# 데이터 로드
data = load_iris()
X, y = data.data, data.target
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 교차 검증으로 최적 K값 찾기
param_grid = {'n_neighbors': range(1, 21)} # K값 후보 1~20
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("최적 K값:", grid_search.best_params_['n_neighbors'])
print("최적 정확도:", grid_search.best_score_)
예제
데이터 예시:
테스트 데이터가 아래와 같다고 가정하자.
- 테스트 데이터: (5.5, 2.5)
- 학습 데이터:
- (5.0, 2.0, 'A')
- (6.0, 3.0, 'B')
- (5.5, 3.5, 'B')
- (4.5, 2.0, 'A')
- (5.5, 2.0, 'A')
1. 거리 계산: 테스트 데이터와 학습 데이터 간의 유클리디안 거리를 계산한다.
예를 들어, 테스트 데이터와 첫 번째 데이터 간의 거리는 다음과 같다:

모든 데이터에 대해 거리 계산을 완료하면 다음과 같은 결과가 나온다:
- (5.0, 2.0, 'A'): 0.71
- (6.0, 3.0, 'B'): 0.71
- (5.5, 3.5, 'B'): 1.0
- (4.5, 2.0, 'A'): 1.12
- (5.5, 2.0, 'A'): 0.5
2. K개의 이웃 선택: K=3일 때 가장 가까운 3개의 데이터를 선택하면:
- (5.5, 2.0, 'A')
- (5.0, 2.0, 'A')
- (6.0, 3.0, 'B')
3. 다수결 투표: K=3일 때, 클래스 A: 2개, 클래스 B: 1개. 따라서 테스트 데이터는 클래스 A로 분류된다.
>> KNN은 데이터를 저장만 하고, 새로운 데이터를 입력받을 때 거리 계산을 통해 예측을 수행한다. K값은 알고리즘의 성능을 결정짓는 핵심 파라미터로, 적절한 값은 데이터 특성과 검증 과정에서 찾아야 한다. 모델은 간단하지만, 데이터 규모와 차원에 따라 효율성과 정확도가 크게 달라질 수 있다.
'👩🏻💻 AI 과정 > 정리노트' 카테고리의 다른 글
| 파이썬 자료구조 - 튜플, 딕셔너리, set, 리스트, 클래스, 객체지향언어 특징 (0) | 2025.01.28 |
|---|---|
| 딥러닝 학습 순서 (0) | 2025.01.16 |
| [GPT랑 공부하기] 이미지 데이터 분석: 기술통계, KNN 분류, 커머스 활용과 네이버 API 연계 인사이트 (0) | 2025.01.14 |
| [GPT랑 공부하기] 컴퓨터 비전과 OpenCV 라이브러리 (0) | 2025.01.14 |
| [데이터분석 커리어패스] 어떤 커리어가 나에게 맞을까? (0) | 2025.01.10 |