1112_가상환경의 이해.pptx
구글에 “가상환경(Virtual Machine)” 검색
오늘 작업환경 셋팅할 예정이고, 왜 클라우드를 해야하는지 알게 될 것이다.
파이썬에서 가장 힘든 것은 의존도가 높아져서 뭔가가 바뀌면 덩달아서 내가 하는 것보다 바뀐거에 쫓아다녀야 한다. 하나가 바뀌는게 아니라 연관되어있는 릴레이션이 꽤 많다. 이런 릴레이션 의존성이 너무 높아서 하나를 설치하고 나머지 의존되어있는게 문제있으면 전체 프로그램이 안돌아가는게 생겨버린다. pandas, numpy, open cv 다 하다보면 몽땅 다 안되는 경우가 생긴다. 그러면 어떻게 하느냐? 구조를 잘 만들어야 한다. 그것을 가상환경이라고 한다. 내가 원하는 모듈만 버전별로 만들어 놓는다. 이거를 안 맞춰놓으면 잘되던 프로그램이 아예 안돌아갈 수도 있다.
파이썬에서 가장 좋은 점은 오픈소스라는 점이다.
우리가 하려는 파트는 오픈 API 챗봇이다. GPU가 설치되어 있어서 GPU 기반으로 셋팅하면 좋지만, 집에가서 하려면 GPU가 셋팅이 안되어있기 때문에 CPU기반으로 셋팅할 것이다. 오픈 API 챗봇은 CPU기반에서도 셋팅이 가능하다. 그래서 파이썬 버전을 다운시켜야한다.
아나콘다 프롬프트 열기 → python 엔터
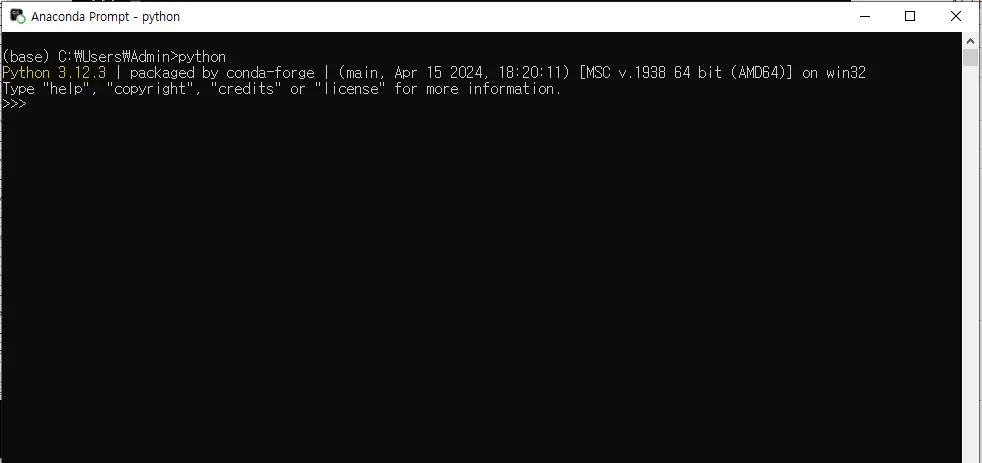
파이썬에다가 오픈 API라고 하는 챗봇 프로그램을 연결할 건데 버전이 서로 맞는지 찾아야 한다.

나갈 때는 exit()
구글 “랭체인” 검색 → LLM을 사용하여 어플리케이션 생성을 단순화하도록 설계된 프레임워크이다. 코드자체가 이해할 수 없는 수준 넘사벽이다. 일반유저는 쓰라는 대로만 쓰면 된다. AI 분야의 개념이다.
프로그램을 근본적으로 만드는 수학, 과학 베이스는 존재한다. 하지만 만드는데 올인하기 전에 만들어져 있는 것을 잘 응용하는 것이 요즘 대세이다. 잘 만들어져있는데도 불구하고 똑같은걸 만들려고 애쓰지 않아도 된다. 하지만 AI쪽은 예외인게 만들어보면 똑같은걸 만들면 의미가 없다. 기본 베이스는 비슷하지만 만들어가는 과정이 데이터마다 다르다. 똑같은걸 만드는 시간이면 이미 기술은 발전해있다고 얘기한다. 아니면 차라리 기존에 있는 걸로 수익화할 수 있는 구조를 생각하는게 의미있다.
구글 “랭체인 파이썬 버전” 검색 → 3.8 버전으로
일단 설치해보고 안되면 버전을 바꿔본다. 이런 것들이 귀찮으니까 클라우드를 사용한다.
구글 “랭체인 샘플” 검색 → 랭체인 모델을 사용해서 여러가지를 할 수 있다.

파이썬 보다는 아나콘다가 쉽다.
base는 프론트라고 생각하면 된다. envs, fcpu는 각각 방이다.

가상환경을 선택한다.
pandas를 설치하는데 판다스를 설치하는 가상환경(tfcpu)을 불러와서 설치해야한다.
1112_가상환경의 이해.pptx 에 있는 페이지 6번까지 작업하기

프롬프트에 “conda create -n tfcpu python=3.8”를 입력하고, Proceed Y or N에서 Y를 입력하면 설치 시작된다.

그러면 폴더가 생기고 설치가 된다.

가상환경 활성화와 종료하기


터미널에서 (tfcpu)활성화한 뒤 pip install pandas 설치한다.



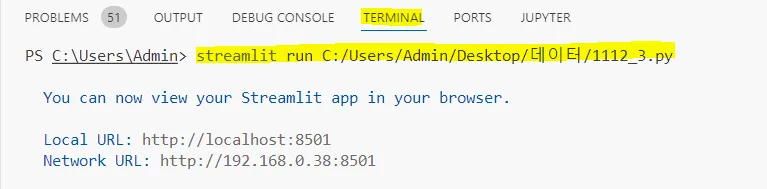
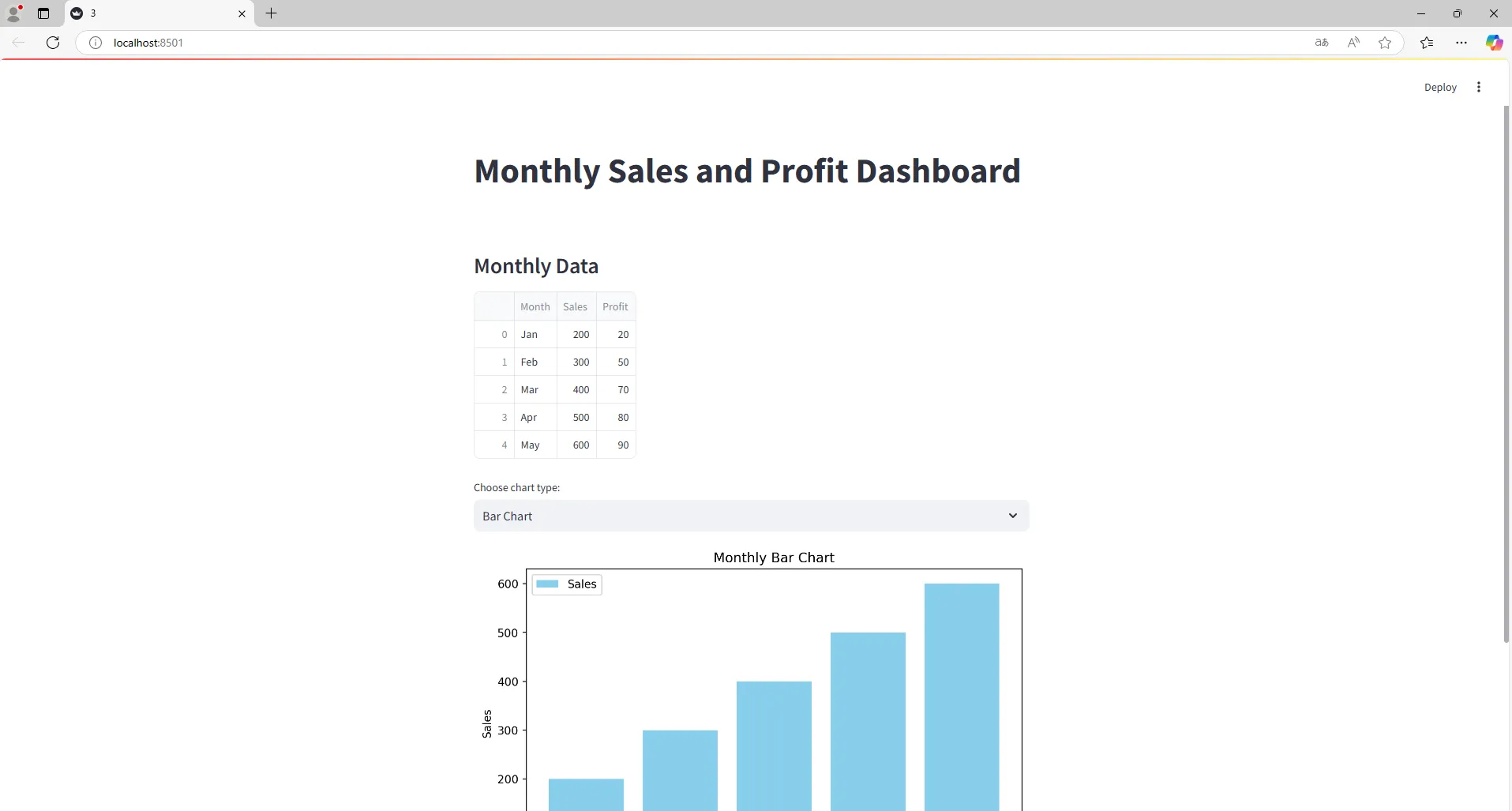
터미널에 아래 코드 실행하면 웹페이지가 뜬다.

자동 저장됨




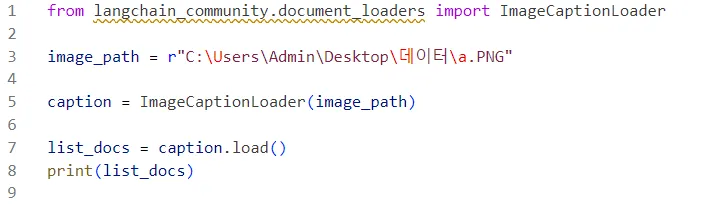
필요한 라이브러리를 설치했다.
| 이름 | 설명 | 예시 | |
| 1 | 모듈 | 가장 작은 단위, 하나의 .py 파일 | math.py, os.py, json.py, random.py |
| 2 | 패키지 | 여러 모듈을 모은 폴더 | requests, scipy, flask, matplotlib |
| 3 | 라이브러리 | 여러 패키지 및 모듈을 포함한 모음 | NumPy, Pandas, TensorFlow, PyTorch, Scikit-Learn |
- 모듈 (Module): 재사용 가능한 Python 코드가 들어 있는 개별 .py 파일이다.
- 패키지 (Package): 관련된 여러 모듈들을 모아 폴더로 구성한 것이다. 패키지는 코드를 잘 조직화하여 큰 프로젝트를 관리하는 데 도움을 준다.
- 라이브러리 (Library): 특정 목적(예: 수치 계산, 웹 개발, 머신러닝 등)을 위해 필요한 패키지와 모듈들의 모음이다. 라이브러리는 일반적으로 하나 이상의 패키지와 모듈들을 포함한다.


가끔 데이터 들어오면 카테고리가 엄청 많아서 빼내서 저장해야한다. 그래서 아래 같은 것이 자동화하는 것이다.

이런 것도 지피티한테 시키면 잘 해준다.

이 코드의 목적은 뉴욕시 임대 데이터 파일(AB_NYC_2019.csv)을 각 동네(neighbourhood)별로 나누어 별도의 CSV 파일로 저장하는 것이다. 이를 통해 특정 이웃에 대한 데이터를 개별적으로 관리하고 분석할 수 있게 된다.
"네트워크 파일" → "웹 프레임워크" → "HTML”
구성해도 나만 보는 거다. 누군가가 보려고 하면 공간을 사야한다. 남한테 줄 수 있는 공간을 사야한다. 대박 어려운 것은 샘플 시연하는 것 정도야 로컬에서 할 수 있지만, 지피티와 같이 네트워크 자료를 봐야하기 때문에 뒤죽박죽 어려운 것이다. 지피티 관련한 라인들은 요즘 다 스트리밍 방식으로 처리하고 있다.

프로그래밍은 내가 쓴 게 아니면 의도를 파악하기 쉽지 않다. 하나씩 실행해보면서 알아내가야한다.
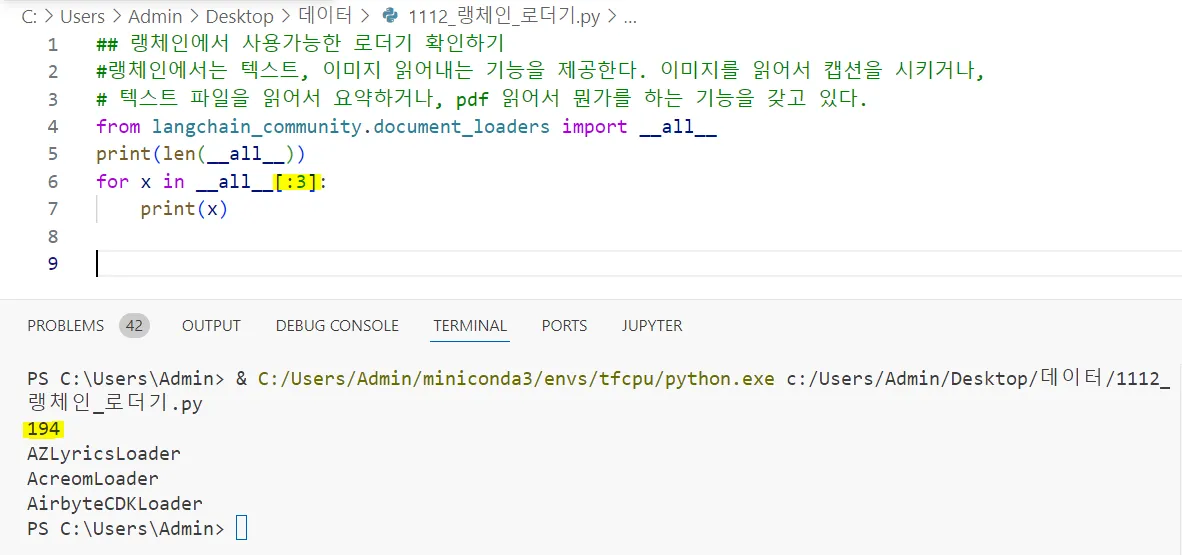
위로 몇개만 보는 것을 항상 해줘야 한다. 위로 몇개만 얼른 보는 작업들이 [:3] → 샘플링 하는 것이 중요하다.
총 194개

파이썬에서는 이런 방법에서 cnt=cnt+1 → cnt+1
하나하나하나 증가하는 구문이 enumerate이다. 구문 자체에 cnt+1 알아서 하나씩 증가해준다. 파이썬만의 독특한 구문이다.

문장 → 단어(토큰) → 벡터 [ 여기까지 GPT ] → 유사도 검색
유사도 검색 끝나면 벡터화해서 → 토큰 → 문장화해서 보여준다.
웹사이트 크롤링은 직접 해야 한다. 일단 pdf 요약기능도 텍스트만 있는 것은 좋은데 이미지가 있거나 표가 있으면 안된다. 그건 유료버전이다. 여기에서 제공하는 기능에서는 도큐먼트 로더기가 있다. 오픈 AI에 맞춰서 문서를 읽어서 문장을 단어화시켜주는 객체화를 시켜주는 로더기이다. 현재 상황에서는 이게 가장 좋다.

챗봇하는 사람들은 이것만 5개월을 배운다. 텍스트 마이닝의 원리부터 시작해서 텍스트가 쪼개지는 방법론, 텍스트 형태소가 무엇인가부터 배운다음에 챗봇을 배운다. 이게 원칙이다. 하지만 작년 12월부터는 이게 안된다. 세상이 바뀌었기 때문이다. 지금은 이것부터 하는게 맞다고 생각한다.

똑같은 질문을 하지 않더라도, 가장 비슷한 유사도를 가진 질문의 질문값을 출력해낸다.

중요한 것은 이미지 하나를 넣고 싶다고 할때, 내 컴퓨터에 있는 이미지를 보지 못한다. streamlit에 저장했던 것 처럼, 이거는 공개해야한다. 최종적으로는 이런 FAQ를 만드는 것이다.
고객응답사이트, 질의응답 많이 올리니까 고객응답매뉴얼이 될 수도 있고, 보험 가입 매뉴얼이 될 수도 있고, 상담원들이 고객하고 응답을 해야하는데 이런 질문이 들어왔을 때는 어떻게 해야하나요?라는 응답매뉴얼도 있다. 챗봇을 통해서 내부적으로 해야하는 매뉴얼일 수도 있다. 지금 당장 공부하는데 있어서 필요한 질의응답이 될 수도 있다. 뭐가 됐든 간에 질문에 대한 답을 찾는 데 있어서 우리가 원하는 질문이 똑같은 질문이 아니여도 결과를 찾을 수 있다. 질의 응답에 해당하는 파일을 우리가 만드는 것이 중요하다. 질문에 대한 답을 찾을 수 있는 시대는 왔다. 그렇기 때문에 어떤 파일을 만들 것인지 생각하는 것이 중요하다. 그리고 기술이 그렇게 어렵지 않다는 것을 알아야 한다. 로더기의 종류를 알아야하는 이유는 이런 어마어마한 기술들이 있고, 이런 기술들이 어렵지 않다는 것을 이해하라는 것이다. 이 기술들을 어디에 쓸지 생각해야 한다. 우리가 해야할 일은 우리가 하려고 하는 것, 가고자 하는 곳에서 어떤 데이터 셋으로 이런 기술을 구현하면 오 좋다~이런 소리 들을 것인지 생각하라는 것이다. 왜 해야하는지 타당성도 생각해야한다. 예를 들어서 보험사 상품이 나왔는데 전 상품이랑 비교해 보고 싶다고 했다. 리걸 쪽에서는 용어들이 통일되어있지 않은 경우가 많다. 우리가 예를 들어서 계약, 급여라고 하면 임금이라는 곳도 있고해서 용어가 표준화되어있지 않다. 문서를 하나 찾을 때도 빠르게 못찾는 경우가 있다. 중요한 문구라던지, 한번 걸러서 봐야하는 부분을 노란색으로 칠해주기도 하면 조금 더 일일히 찾는 것보다 빠를 수 있다. 이런것이 AI이다. AI는 엄청 거한 것을 하는 것이 아니다. 그냥 맨 아래 직원이 하는 것을 하는거다.
Summary: 질의응답 매뉴얼이나 챗봇을 통해 고객과 상담원, 내부 직원들이 필요한 답을 쉽게 찾을 수 있는 시스템을 구축하는 것이 중요합니다. 기술 자체는 어렵지 않으며, 데이터를 활용해 효율적으로 문제를 해결하는 것이 핵심입니다. 목표는 어떤 데이터와 기술을 사용해 업무를 개선할지, 그 타당성을 잘 판단하는 것입니다. AI는 복잡한 것이 아니라, 반복적이고 간단한 업무를 대신하는 역할을 수행합니다.
https://pythonmldaily.com/lesson/python-chatbot-langchain/intro-tools-plan-of-action
01 - Intro: Tools and Plan of Action | Python ML Daily
The most typical usage of AI these days are chatbots, personal assistants, or customer support agents. In this tutorial, let's build a chatbot that would answer customer's questions based on our answers from the FAQ document. Our "knowledge base" FAQ will
pythonmldaily.com

'👩🏻💻 AI 과정 > AI & DT 교육' 카테고리의 다른 글
| 인공지능과 생성형 AI (7) ChatGPT API (0) | 2024.12.05 |
|---|---|
| 인공지능과 생성형 AI (6) 랭체인, LLM, LCEL (6) | 2024.12.05 |
| 인공지능과 생성형 AI (4) Tkinter 패키지, GUI 구현, 파이썬 (함수 / 패키지 / 모듈) (3) | 2024.12.05 |
| 인공지능과 생성형 AI (3) 디렉토리, 터미널, pathlib 모듈 (0) | 2024.12.05 |
| 인공지능과 생성형 AI (2) Gemini API, 멀티턴, temperature (1) | 2024.12.05 |