추천시스템
비슷한 취향의 사람을 연결해주는 것이다. 넷플릭스라면 유사도가 비슷한 사람이 본 것을 보여준다. 우리가 구현을 못하는 이유는 실제 데이터가 없으면 구현을 못한다. 파이썬이 제공하는 모듈로는 택도 없다. 파이썬이 제공하는 모듈로 추천시스템을 구현안한다. 일반 모듈로는 못쓴다. 거기다가 플러스해서 붙여야한다. 그런 부분들은 추천으로 해서 잘 됐는지는 실제 데이터가 필요하다. 추천시스템은 데이터를 가지고 어떤 알고리즘을 쓰는지가 중요하다. 시중에 나와있는 알고리즘이 아닌 다른 요소들을 찾아내야 한다. 넷플릭스는 사용자 취향에 따라서 추천해주는데 한국이라면 계절도 있고 다른 요소들도 있다.
설계라는 것은 엄청 나게 많이 알아야 할 수 있는 것이다. 쓸데 없는 설계는 안하는게 낫다. 이론으로 완전 무장하면 설계를 할 수도 있다. 이론적 무장을 해야하는데 이론이 안와닿아서 IT는 하는거랑 배우는 거랑 매우 다르다. 프로그램만 짠다고 되는 게 아니다. 아이디어가 있다고 되는게 아니다. 플랫폼, 웹인지 앱인지 여러가지의 환경적인 요소들도 엄청 고민해야 한다. 그렇기에 이론으로 무장해서 되는게 아니라서 써봐야 한다.
스마트팜을 LLM 한다고 하면 새벽4시가 되면 닭소리가 나니까 소리로 인지할거라서 그런건 어떻게 할지? 현장을 모르면 모른다. 모든 것은 겪어봐야 한다.
파이썬 교재 ‘원리가 보이는 파이썬 빅데이터 분석 기초와 실습’
파이썬 자료 구조 - 튜플, 딕셔너리, set, 리스트, 클래스, 객체지향언어 특징
리스트는 딥러닝에서 잘 안쓰인다.
p.45
#얕은 복사
a=[1,2,3,4]
b=a
b[2]=0 #b=[1,2,3,4] → [1,2,0,4] 이렇게 b를 바꾸면 a값도 바꾼다 (얕은 복사)
할당이라고 하는데 얕니, 깊니 이런 용어를 쓰게 하는게 파이썬이다.
깊은 복사는 b는 b고, a는 a다. 백업본 만들어 놓는다. 판다스 작업할 때는 깊은 복사 사용한다.
#append: 머신러닝 쪽에서 많이 나온다.
append()는 파이썬에서 리스트에 새로운 요소를 추가하는 메서드다. 이 메서드를 사용하면 기존 리스트의 끝부분에 새로운 요소를 추가할 수 있다. 즉, 리스트의 크기를 동적으로 늘릴 수 있게 해준다.
a=[]
a.append([])
print(a)
a[-1].append(100)
print(a)
a[-1].append(200)
print(a)
a.append
리스트(list)란? 여러 개의 값을 하나의 변수에 저장할 수 있는 데이터 구조이다. 다양한 자료형을 함께 담을 수 있고, 크기가 변할 수 있어 굉장히 유연한 데이터 구조다. 파이썬에서 리스트는 대괄호 []로 표현하며, 각 요소는 콤마로 구분한다.
파이썬에서 기초 공부하면 리스트만 가지고 한달을 할 수 있다. 해봐야 의미 없다. 프로그래밍 지식을 쌓는데는 의미가 있을지도 몰라도 공부해도 어디에 쓰이냐면 엄청 고급에 가야 쓰인다. 딥리닝 쪽으로 가면 리스트는 그냥 단순 문법이라서 오래잡고 공부할 내용이 아니다. 컴프리헨션, 슬라이싱
extend()는 파이썬 리스트의 메서드로서, 딥러닝에서 데이터를 다루는 과정에서 extend() 메서드를 사용할 수 있는데, 특히 데이터 전처리, 배치 생성, 여러 데이터셋 병합 등에 유용하다. 딥러닝에서 종종 자주 쓰인다.
튜플(Tuple)은 여러 개의 값을 하나의 변수에 저장할 수 있는 순서가 있는 컬렉션이다. 인덱스에 다이렉트로 접근할 수 없다. (튜플과 리스트의 차이점)

사이즈를 변형하기 위해서는 함수 resize를 쓰면 된다.

튜플도 머신러닝, 딥러닝으로 가야 자주 보이는 구조이다. 그 전에는 자주 안보인다.
set은 데이터 중복에 좋은데 인덱싱이 안된다. sort 되서 나온다. 인덱싱 하고 싶으면 리스트로 바꾸면 된다.

클래스
우리가 하는 설계와 프로그래머들이 하는 설계가 다르다. 프로그래머들이 모듈에 집착하는데 이유는 재사용성 때문이다. 프로그램은 최대한 작게 만들어서, 재사용하고, 불필요한 부분만 도려내도, 다른 부분은 문제없어야 하고, 어떤 부분만 복사해서 다른 곳에 갔다가 써도 되게 해야한다. 이게 다 객체지향 언어라고 한다. 언어는 객체지향 언어와 절차지향언어로 나뉜다. 하나하나 차근차근 내 손으로 만들어서 써야하는 절차지향이 있고, 내가 만든 것을 객체화해서 가져다 쓰는 것을 객체지향언어이다. Tkinter가 객체지향언어이다. 게임이 가장 대표적인 객체지향언어이다. 자바나 파이썬이 설치가 오래걸리고 무겁다는 특징이 있는데 그 이유가 얘네는 객체지향언어이기 때문이다.
자동차는 바퀴, 차문이 따로따로 있다. 찍어내게 되면 색상만 따로해서 찍어낼 수 있기 때문에 인스턴스를 생성해서 객체를 생성할 수 있다.

비트코인은 블록체인인데 보안빼고(넘사벽임), 설계도 넘사벽이다. 구조설계는 배워서 할 수 있는 부분이 아니다. 근데 코딩은 가능할지도 모른다. 보안이 넘사인 분야가 블록체인, 클라우드다. 설계는 단기간에 배워서 할 수 있는게 아니다.
머신러닝, 딥러닝에서 클래스를 배우는 이유는 프로그래머들이 클래스로 주기 때문에 이해하기 위해서 배우고 있다. 클래스를 잘해야겠다고하면 프로그래밍 자체를 잘해야한다. 그래야 클래스를 잘 쓸 수 있다. 파이썬 클래스 문제가 아니다. 그냥 클래스 문제다.
클래스는 self라는 명령어가 있다.
요즘 지피티가 잘하는 것이 코드를 짜서 클래스로 변경해달라고 하면 진짜 잘한다. 이제는 클래스로 해주는데 클래스 상속해주는 것도 가능하다. 쪼개는 이유는 불필요한 건 안하기 위해서다. 예) 네이버 API 연결 코드 → 클래스로 변경 → 클래스 상속해줘
프로그래밍에 관심이 있다면 무조건 클래스 변경하는 것을 할줄 알아야 한다. 지피티 없이 짜는 습관이 들여야 한다.
모듈, 패키지(교재 p115-124)는 읽기만 해도 됨 → 개념은 반드시 알아야 함, 추후 동작 인식하는 미디어파이프에서 이 모듈, 패키지 별로 작업이 들어오는 게 많아서 이해도가 있어야 함.
오늘 오후 수업에서는 네이버 API자료 가져와서 판다스에서 작업한다.
- 네이버 API 가져오기
- 판다스의 시리즈와 인덱스 (교재 p132-149)
이제 자료는 구글드라이브아닌 Git에 올라올 예정이다. ipynb 열기가 편하다.



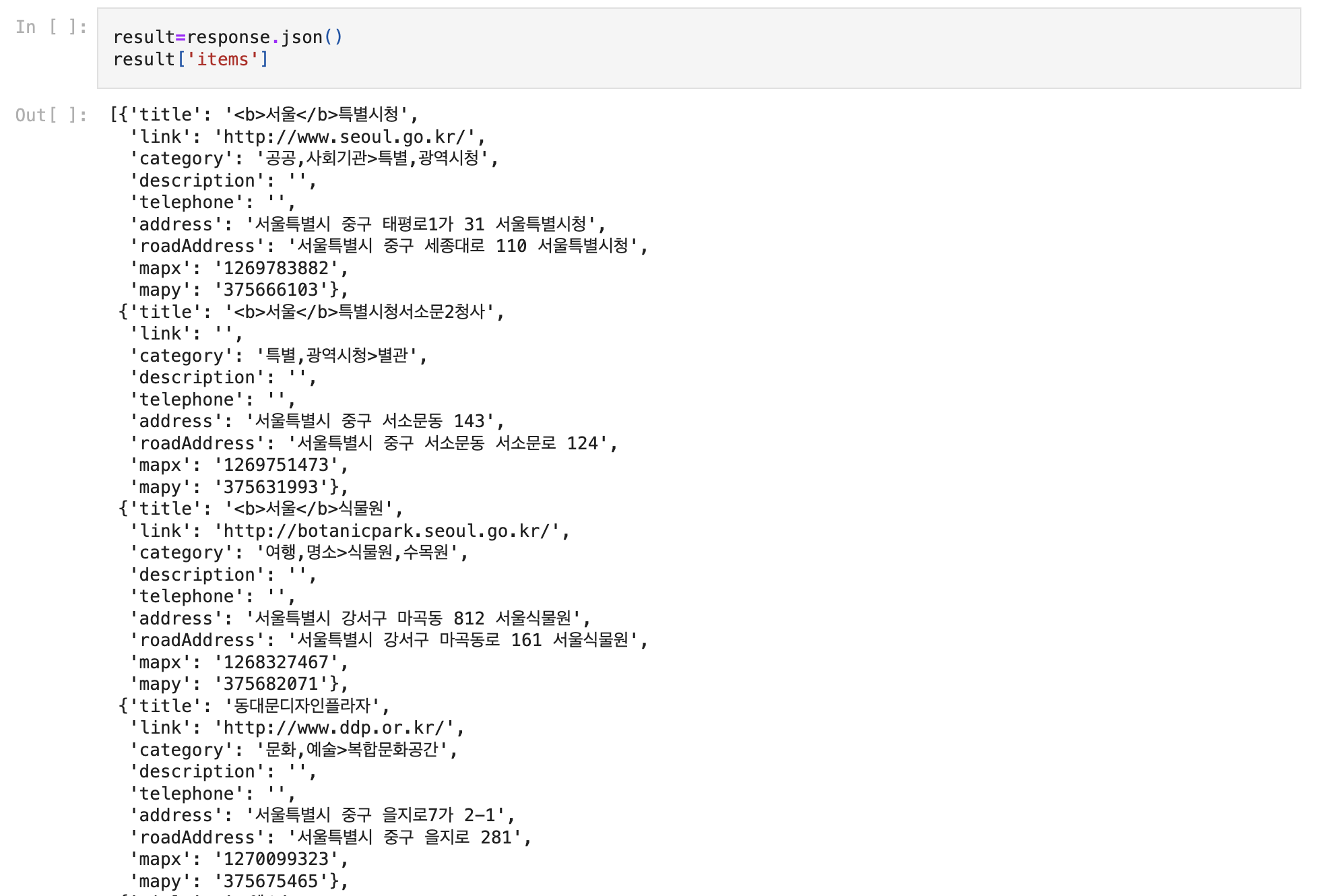



import requests
import pandas as pd
def makeUrl(findAPI):
try:
apiEndPoint=dict({'블로그':'blog',
'뉴스':'news',
'쇼핑':'shop',
'책':'book',
'영화':'movie', # 23년 서비스종료
'지식': 'kin',
'지역':'local',
'카페':'cafearticle',
'지식백과':'encyc',
'학술정보':'doc'})
makeAPI=apiEndPoint[findAPI]
endPointUrl=f'https://openapi.naver.com/v1/search/{makeAPI}.json'
print(endPointUrl)
return endPointUrl
except:
print('요청한 {findAPI} 없음, 뉴스/쇼핑/책/영화/지식/지역/카페 만 가능')
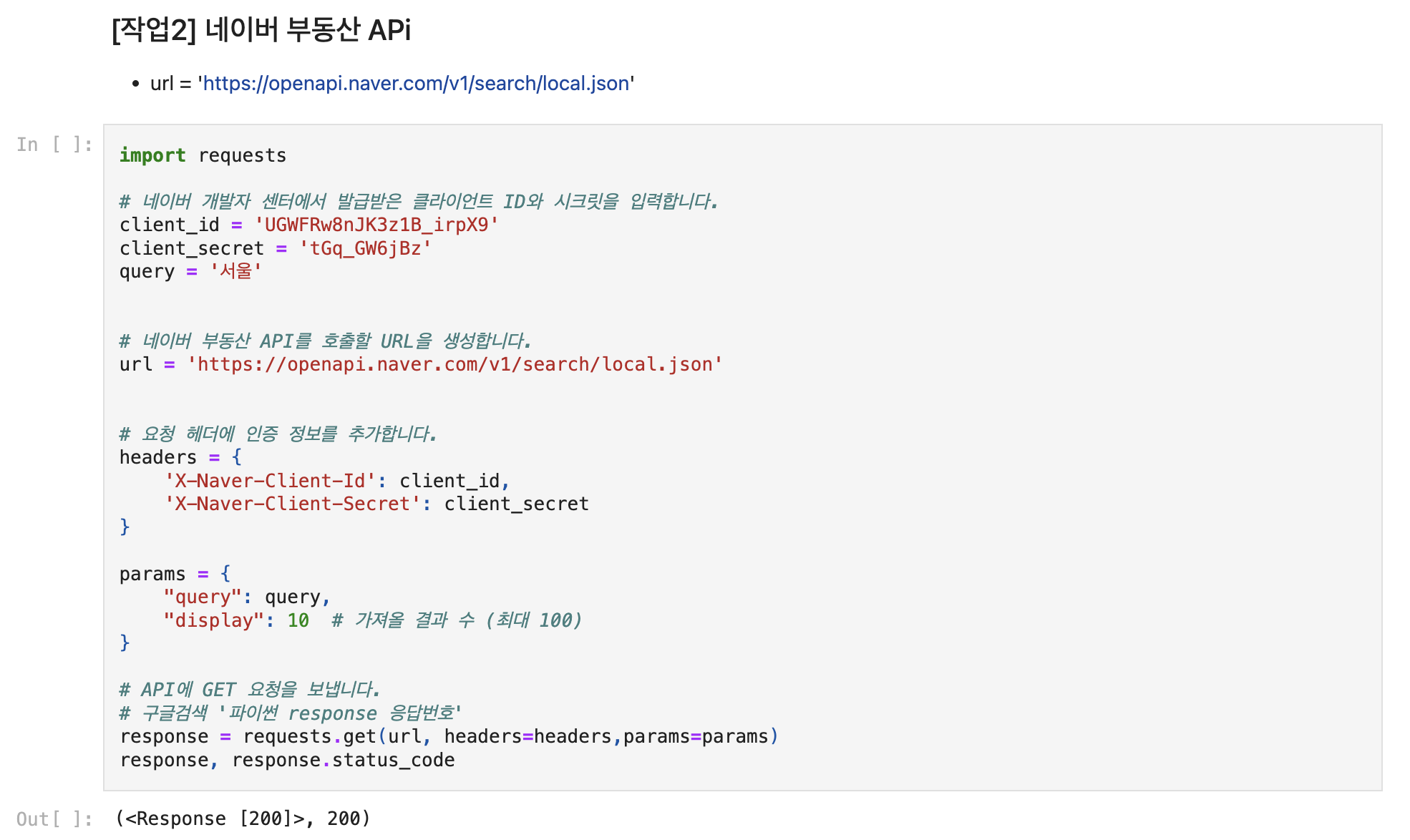
def naver_api(url, query,display=10):
client_id = 'Your ID'
client_secret = 'Your Password'
# 요청 헤더에 인증 정보를 추가합니다.
headers = {
'X-Naver-Client-Id': client_id,
'X-Naver-Client-Secret': client_secret
}
params = {
"query": query,
"display": display # 가져올 결과 수 (최대 100)
}
# API에 GET 요청을 보냅니다.
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
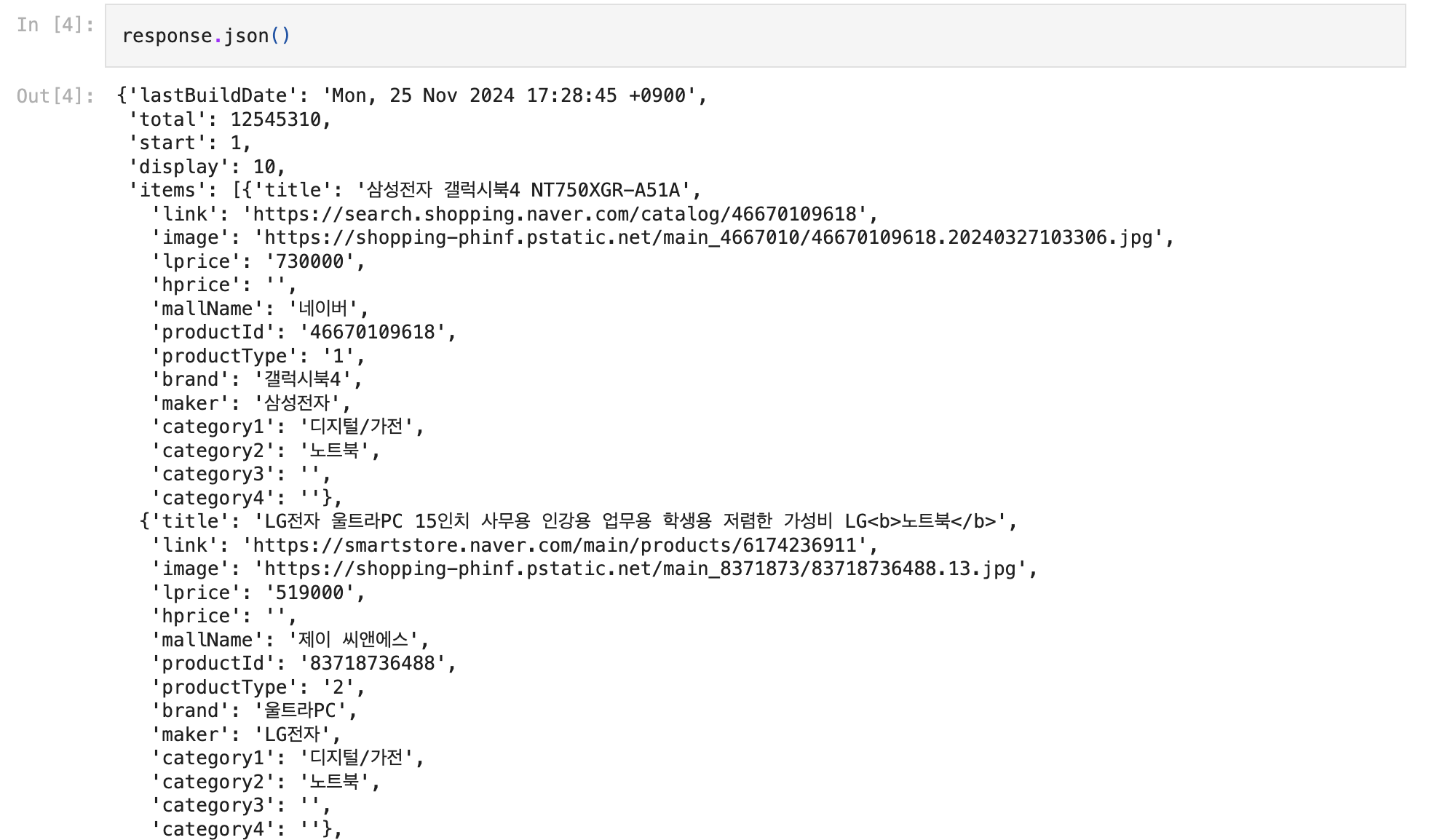
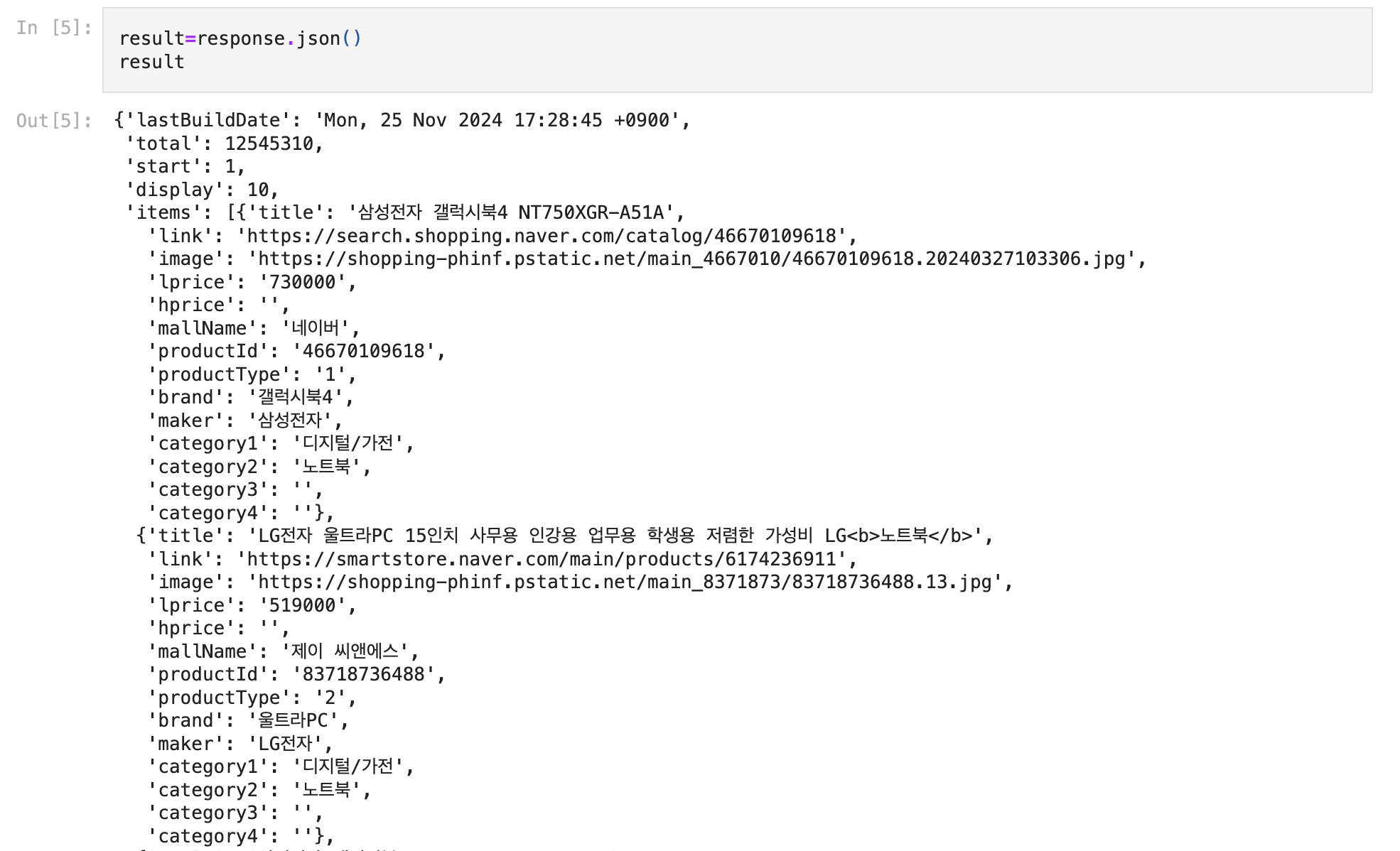
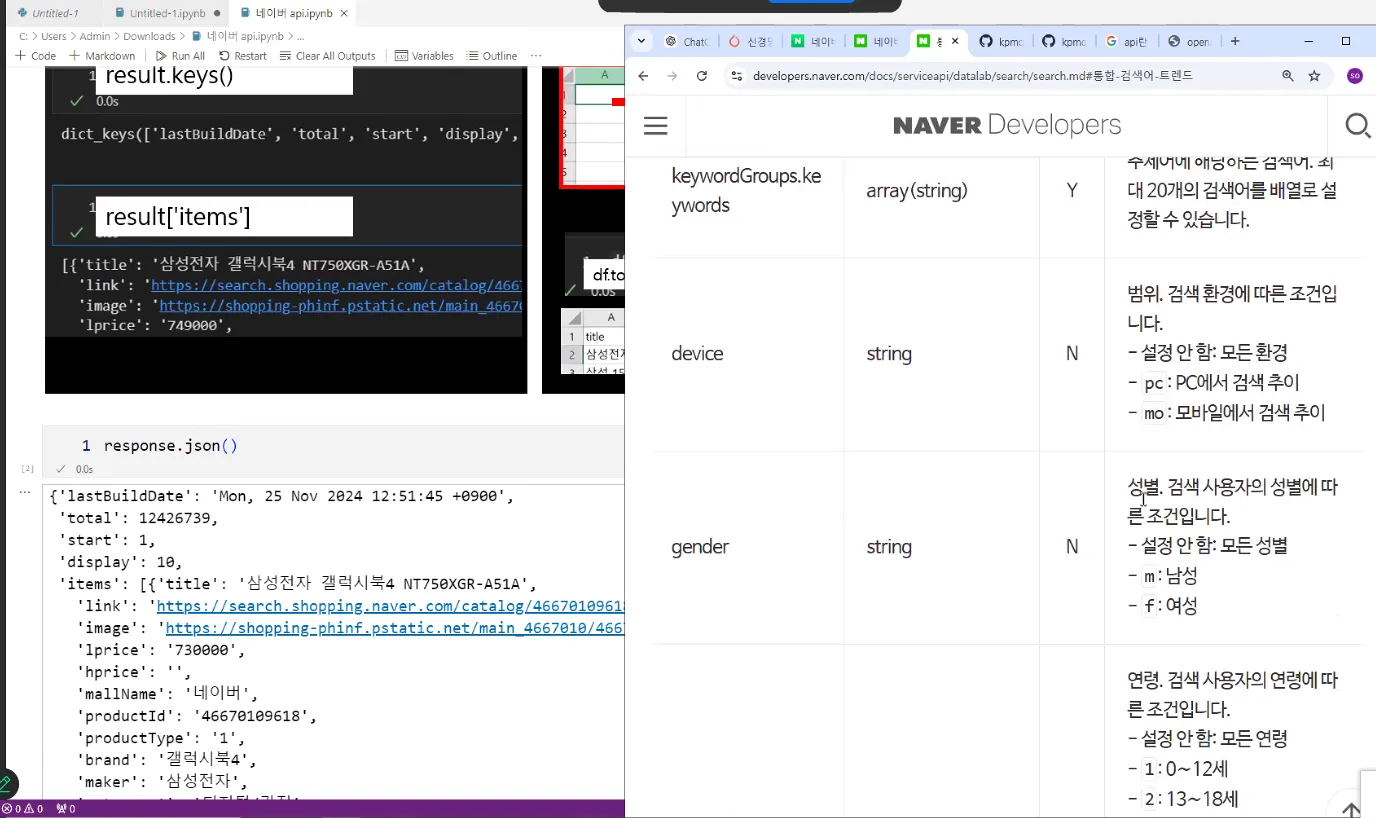
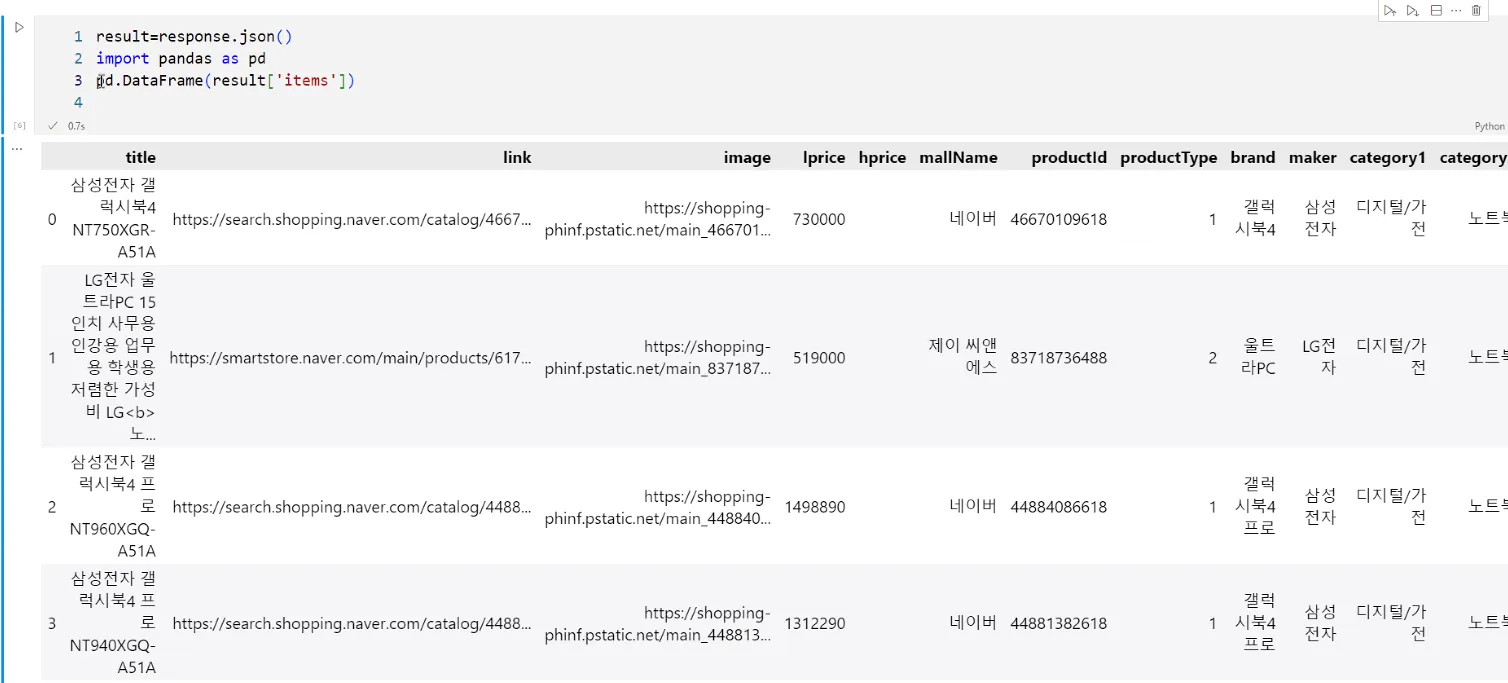
result = response.json()
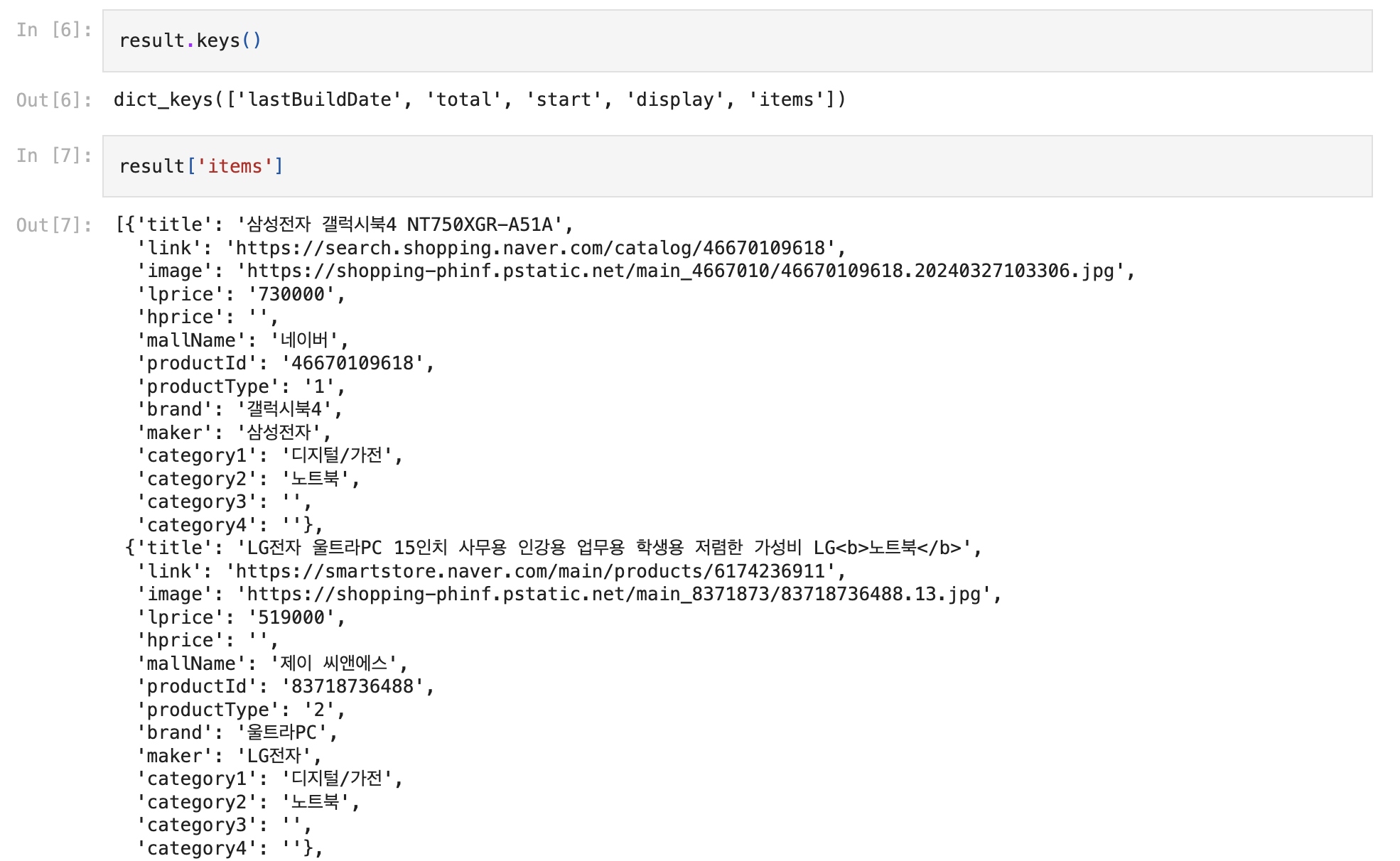
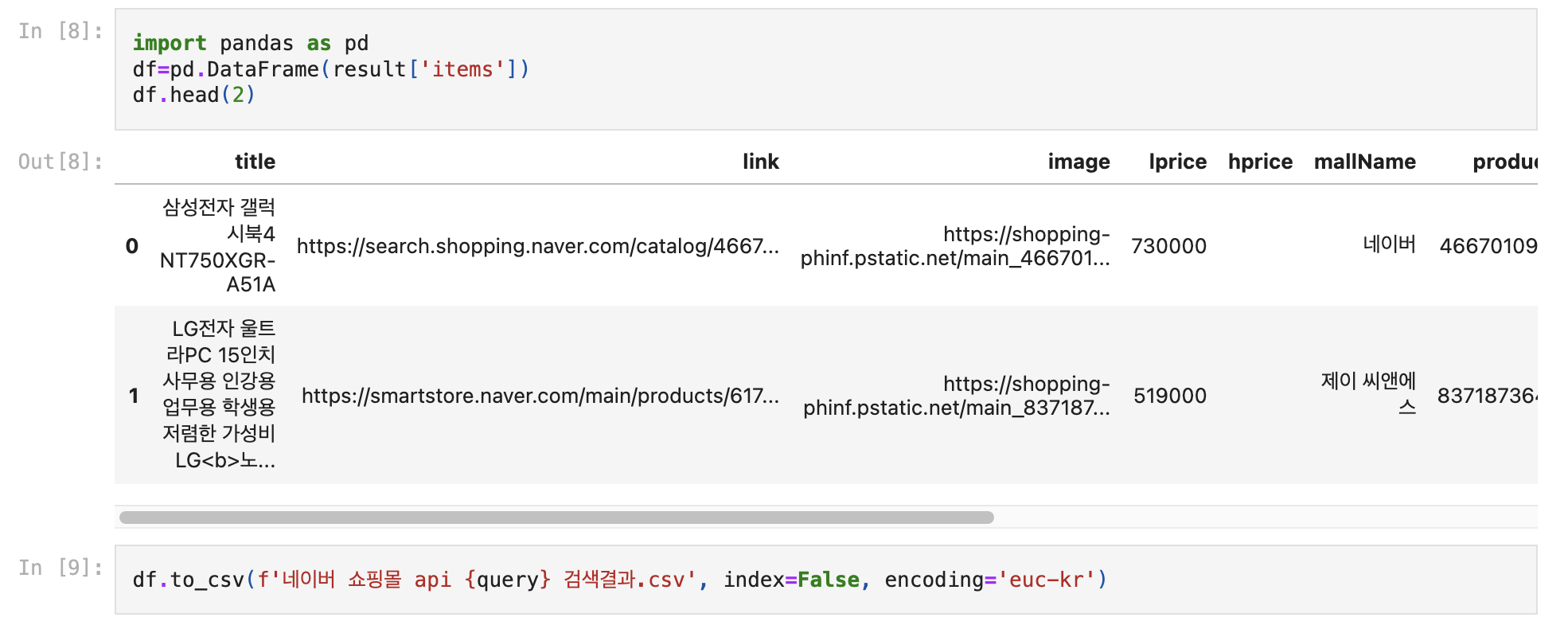
df = pd.DataFrame(result['items'])
return df
else:
print("Error:", response.status_code)
return None
api,query='책','파이썬'
url=makeUrl(api)
df=naver_api(url,query,100)
df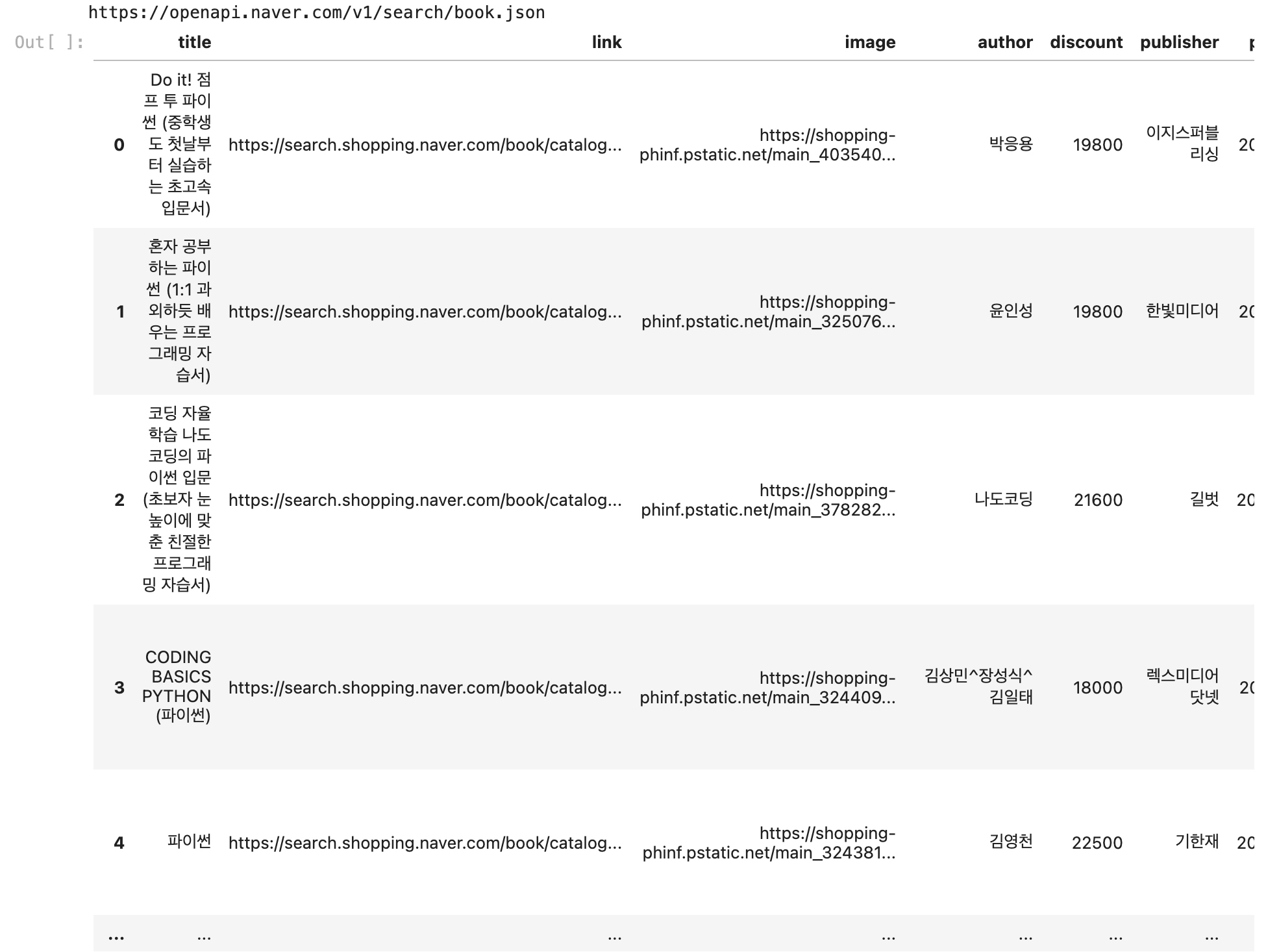

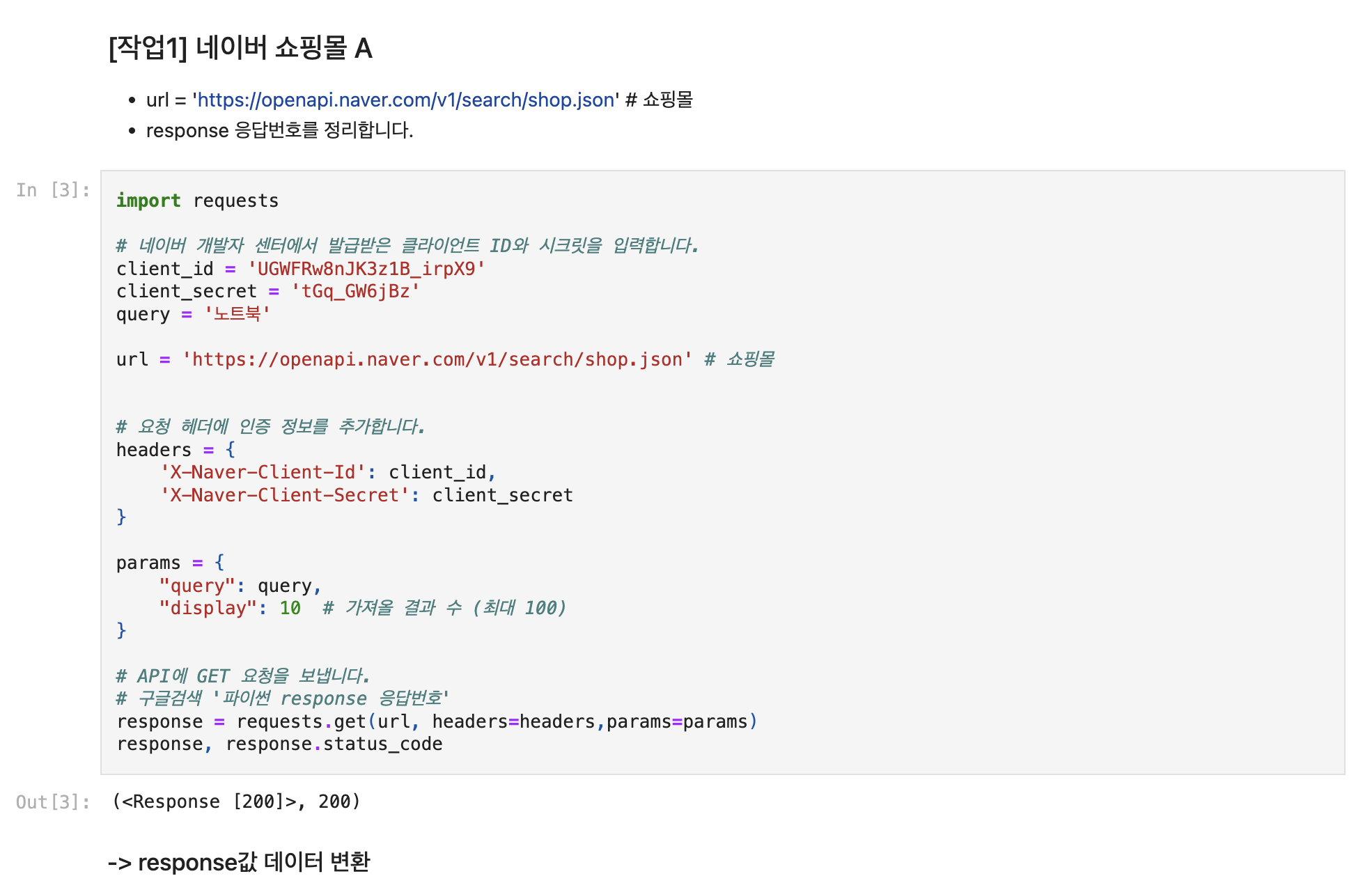
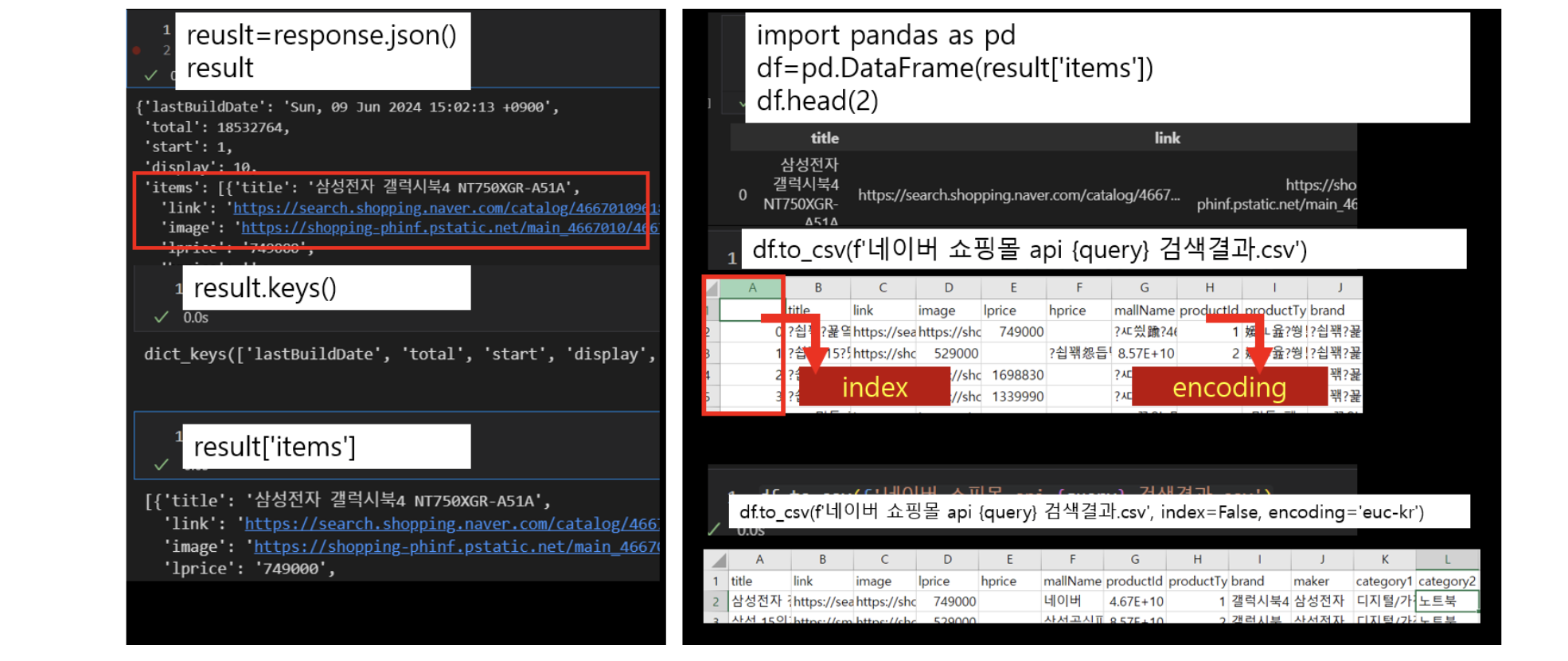
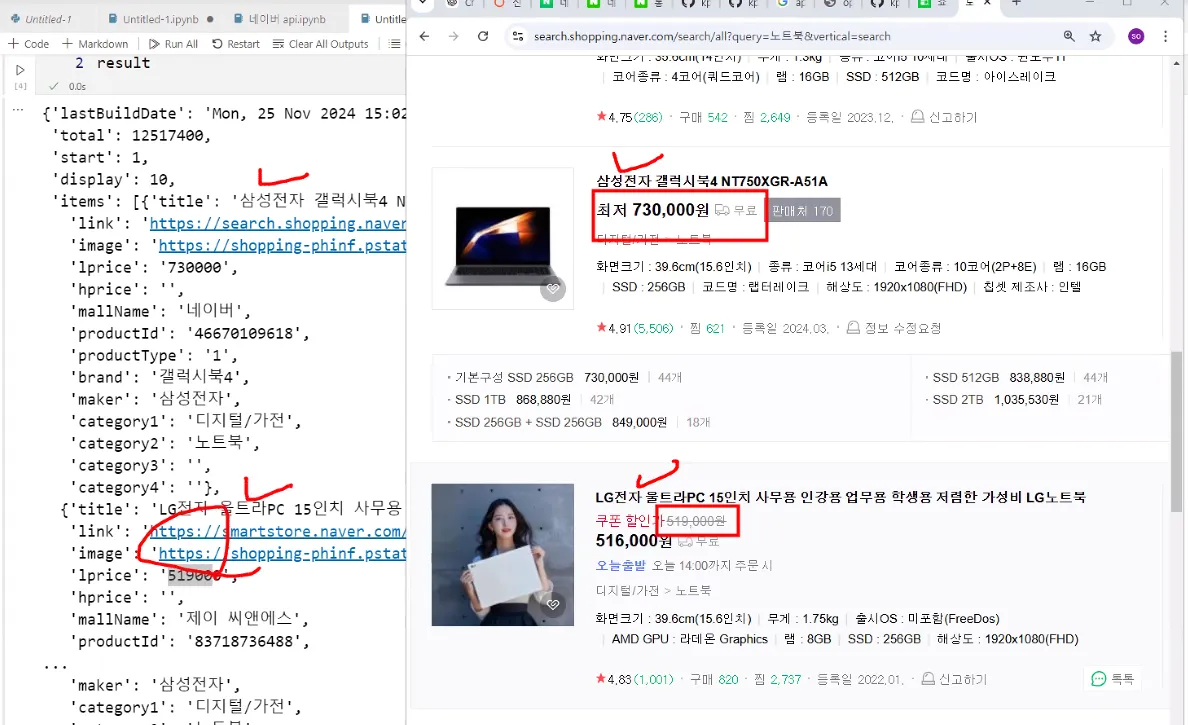
df.to_csv(f'네이버 {api} api {query} 검색결과.csv', index=False, encoding='euc-kr')네이버 오픈 API를 사용해 특정 카테고리(예: 책)에서 검색어(예: "파이썬")에 대한 결과를 요청하고, 이를 정리된 표 형태(데이터프레임)로 변환했다.
이렇게 수집된 데이터는 텍스트 분석, 트렌드 파악, 추천 시스템 등에 활용할 수 있다. 자동화하여 특정 키워드와 카테고리에 대해 반복적으로 데이터를 수집해 모니터링도 가능하다.
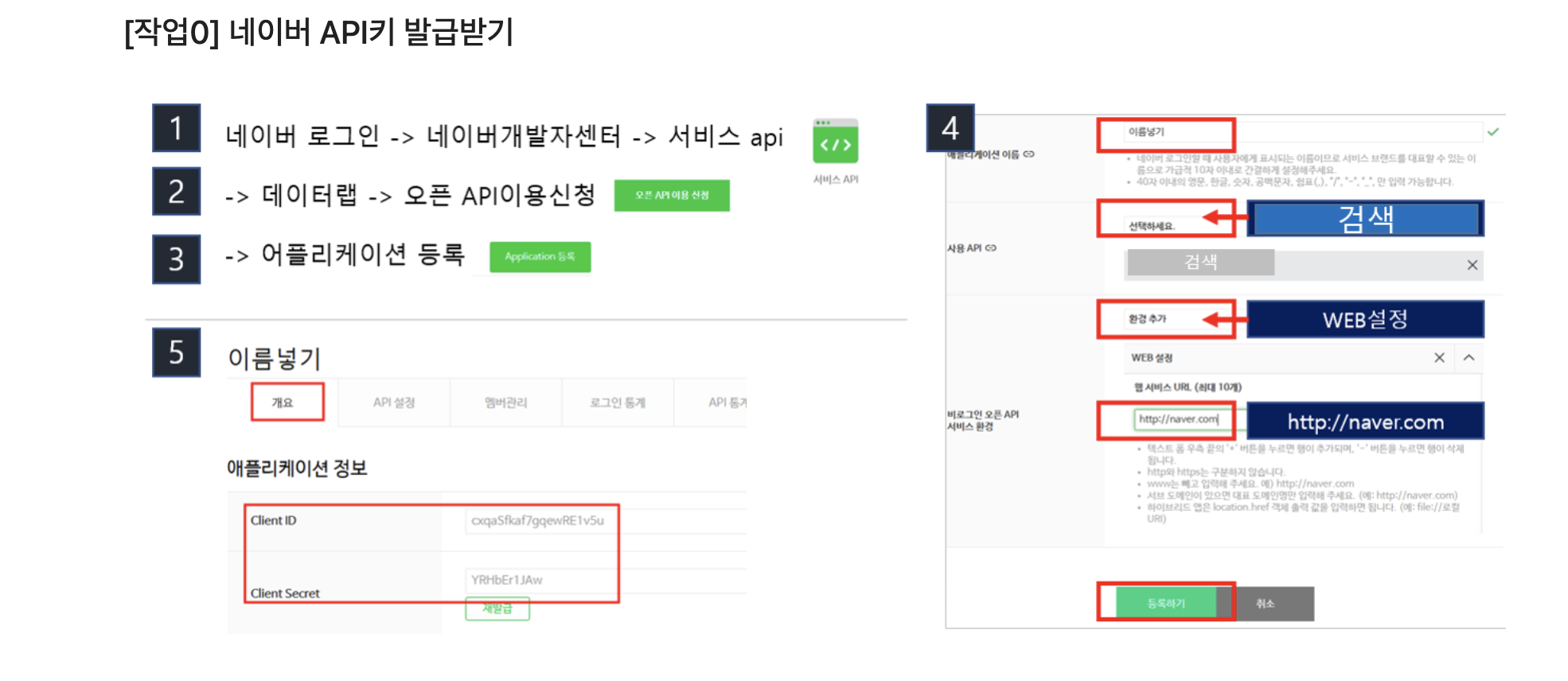
네이버 API 발급
네이버 개발자센터 - 오픈 API 이용신청
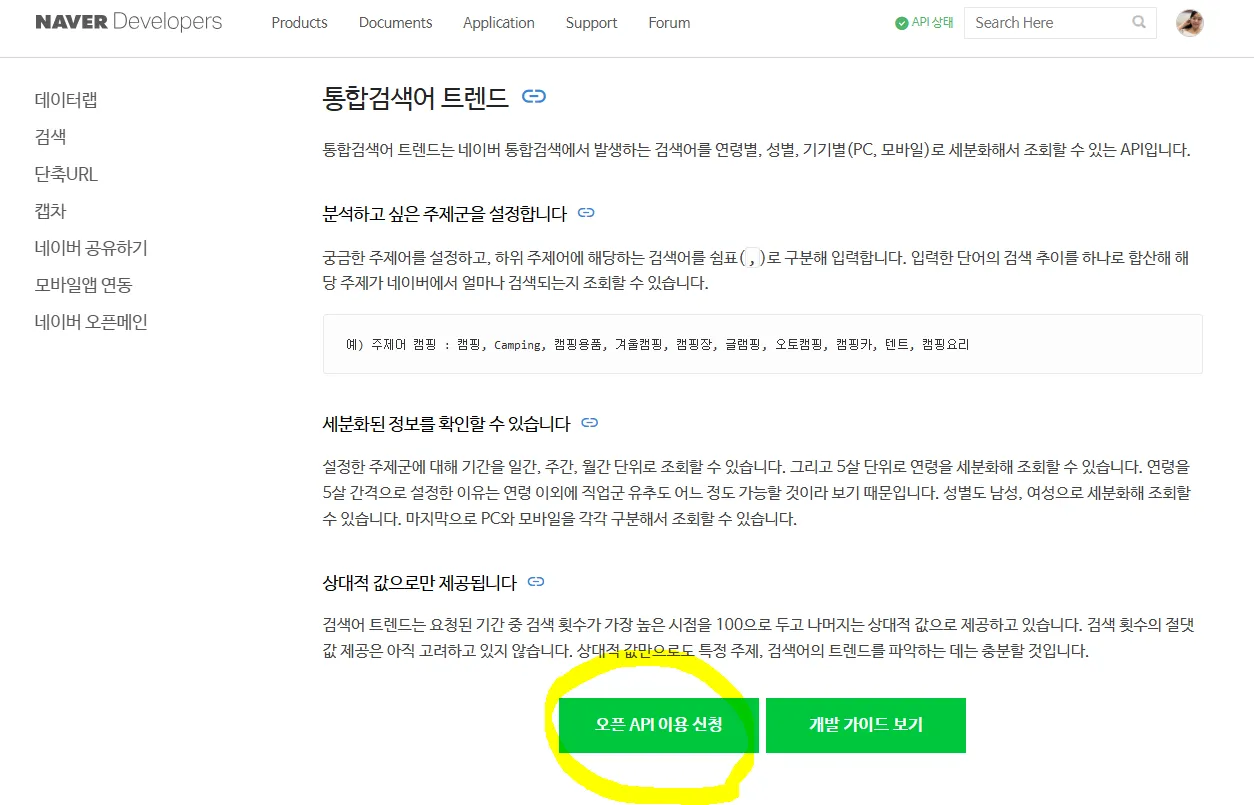

퍼포먼스 마케팅: 구글 애널리틱스, 네이버 애널리틱스 (트렌드 분석)에서 제공하는 key값을 관리자 로그인해서 보면 우리 홈페이지 들어올 때 클릭해서 들어왔는지, 광고에서 들어왔는지 확인하고, 어디에 머물러 있는지 리워드 마케팅하는 것을 전문으로 하는 직업군이다. 데이터 분석 쪽에서 가장 난이도가 낮은 부문이다. 크롤링 잘하는 것은 바라지 않는다. 하지만 API 부분은 우리가 꼭 알아야 한다.
RESTful API: 데이터 수집과 활용의 필수 도구
JSON 형식으로 반환한다.

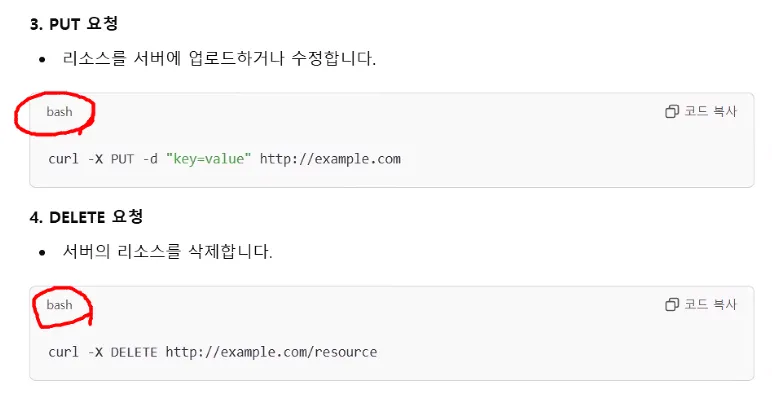
bash는 터미널이다.

자바는 네트워크 전문 프로그래밍 언어다. 네트워크 관련 회원관리 싹 다 자바다. 그것보다 사이즈 작으면서 쇼핑몰과 관련되어있는 것이 PHP이다. C의 기능을 올린것은 C#이다. 게임 프로그램은 C#으로 이루어져있다. 백엔드 쪽은 자바, 요즘 뜨는 것은 Node.js다.


AI 기획자로서 기업들의 API 활용 방법, 내가 직접 개발하지 않는다면 API라고 부른다. 너무 빨리 바뀌는 세상에서 일일히 다 만드는 것보다 만들어진 것을 가져다가 쓰는 것이 비용적으로 유리하다. 지금도 살면서 불편한 것을 생각하면서 새로운 기획을 하는 것이다. 이왕이면 국가가 해야하는 것, 이익을 낼 수 있는 것에 해당하는 것을 생각해야 한다.
API 플랫폼, 엄청 많은 인공신경망 관련된 API가 나오고 있으니까 중요하다.
오픈 API 플랫폼은 무료로 받아올 수 있는 데이터셋이다. 데이터가 있어야 판매를 하든, 분석을 하든 한다. 클라우드는 대용량의 컴퓨터로 같이 처리하자는 의미로 각광받고 있는 것이다. 인공지능, 머신러닝은 빅데이터에 기반해서 나타나고 있다. 빅데이터 기반의 시뮬레이션이 뜨고 있다. 메타공간 안에서 뜨고 있다. 메타 공간 안에서의 기존의 빅데이터를 가지고 시뮬레이션을 하는 것을 디지털 트윈이라고 한다. 빅데이터가 가능한 이유는 큰 저장소에 데이터들을 저장할 수 있게 되었다.
기획자로서 어떤 API를 넣으면 좋을 것인지 기획을 하게 될 것이다. 판매를 프로그래머들이 하지 않는다. 판매는 물건 팔듯이 파는 것이 아니다. 이 용어들을, 대시보드들을 알아야 판매를 한다. 다양한 영역이 있다.
교재 ‘원리가 보이는 파이썬 빅데이터 분석 기초와 실습’ p132
데이터 프레임(구조화된 데이터) vs 시리즈(단일 열 구조)
판다스도 AI가 있다. 판다스는 행과 열로 이루어져 있는 데이터 프레임을 의미한다. 넘파이에 비해서 판다스는 속도가 느리다는 단점이 있다. 엑셀로 백만라인 3개가 있으면 데이터가 많다고 본다. 언제 효과적이면 숫자 문자 섞여있는 데이터에는 좋다. SQL과 같은 데이터 프레임 구조에 좋은 데이터 처리기이다.
시리즈는 제목이 없다. 데이터 프레임과는 다르다. 인덱스는 제목이 없다.
'데이터 AI 인사이트 👩🏻💻 > KPMG 교육' 카테고리의 다른 글
| 비즈니스 애널리틱스 I (3) 텍스트 분할 & 임베딩, 벡터 유사도 분석, 형태소 분석, 네이버 쇼핑몰 데이터 RAG (1) | 2025.01.26 |
|---|---|
| 비즈니스 애널리틱스 I (2) 네이버 API 활용을 통한 데이터 수집, 전처리, 분석, 시각화 (0) | 2025.01.26 |
| 디지털 이노베이션 및 빅테크 AI Business 전략 (3) 허깅페이스, 멀티모달, 컴퓨터 비전 (0) | 2024.12.06 |
| 디지털 이노베이션 및 빅테크 AI Business 전략 (2) 오픈 AI 임베딩, RAG, 파싱, requests 모듈, 웹데이터 구조 (4) | 2024.12.06 |
| 인공지능과 생성형 AI (8) 인코딩 방식, Faiss, csv 로더기 (1) | 2024.12.06 |



