네이버 API 검색
import requests
import pandas as pd
# 네이버 개발자 센터에서 발급받은 클라이언트 ID와 시크릿을 입력합니다.
client_id = 'Your ID'
client_secret = 'Your Password'
query = '직장인'
url = 'https://openapi.naver.com/v1/search/shop.json' # 쇼핑몰
# 요청 헤더에 인증 정보를 추가합니다.
headers = {
'X-Naver-Client-Id': client_id,
'X-Naver-Client-Secret': client_secret
}
params = {
"query": query,
"display": 100
}
# API에 GET 요청을 보냅니다.
response = requests.get(url, headers=headers, params=params)
result = response.json()
df = pd.DataFrame(result['items'])이 코드는 네이버 쇼핑 API를 통해 "직장인" 키워드로 검색한 결과를 Pandas 데이터프레임으로 저장한다.
여기에다가 for문을 더해서 100번 돌린다. (=100번 호출한다)
import requests
import pandas as pd
for x in range(100):
# 네이버 개발자 센터에서 발급받은 클라이언트 ID와 시크릿을 입력합니다.
client_id = 'Your ID'
client_secret = 'Your Password'
query = '직장인'
url = 'https://openapi.naver.com/v1/search/shop.json' # 쇼핑몰
# 요청 헤더에 인증 정보를 추가합니다.
headers = {
'X-Naver-Client-Id': client_id,
'X-Naver-Client-Secret': client_secret
}
params = {
"query": query,
"display": 100
}
# API에 GET 요청을 보냅니다.
response = requests.get(url, headers=headers, params=params)
result = response.json()
df = pd.DataFrame(result['items'])
print(x)이 코드는 range(100) 루프를 추가하여 동일한 API 요청을 반복적으로 수행한다. 반복문 안에서 x 값을 출력하는 코드가 포함되어있다. print(x)는 각 반복 단계의 인덱스를 출력한다.
100개씩 데이터를 돌렸고, 돌린 데이터에서 df로 보여달라고 한다.
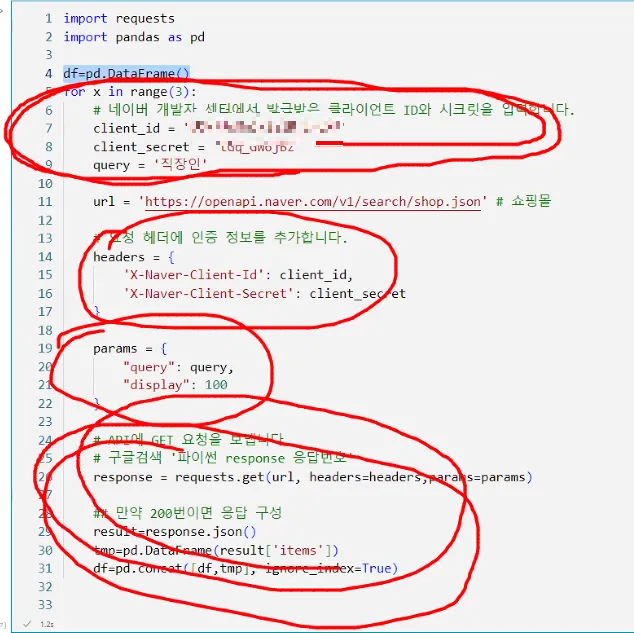
import requests
import pandas as pd
for x in range(3):
# 네이버 개발자 센터에서 발급받은 클라이언트 ID와 시크릿을 입력합니다.
client_id = 'Your ID'
client_secret = 'Your Password'
query = '직장인'
url = 'https://openapi.naver.com/v1/search/shop.json' # 쇼핑몰
# 요청 헤더에 인증 정보를 추가합니다.
headers = {
'X-Naver-Client-Id': client_id,
'X-Naver-Client-Secret': client_secret
}
params = {
"query": query,
"display": 100
}
# API에 GET 요청을 보냅니다.
response = requests.get(url, headers=headers, params=params)
result = response.json()
df = pd.DataFrame(result['items'])
df이 코드는 for 루프를 통해 3번 반복하며 네이버 쇼핑 API를 호출하고, 마지막으로 생성된 데이터프레임 df를 출력한다. df는 각 요청에서 가져온 데이터를 저장하는 데 사용된다.
위의 결과물

display 100이고 3번 돌리니까 300개 여야하는데 출력은 100개밖에 안나온다. 300개가 되려면 100개 추가하고 100개 추가하고 100개 추가하는 것을 해야한다. 이런 작업은 추가라는 것을 해야한다. 판다스가 문법이 조금 바뀌었다. 판다스 버전에 대해서 이해해야 한다. 구글 “판다스 버전에 따른 concat”
보통 append가 추가기능인데 판다스 버전 변동이 있으면서 append 기능이 concat 기능으로 변동이 되었다. 예전 버전으로 제공되는 코드보면 append이지만 버전에 따라서 나오는게 다르다.
이에 따른 해결책은 아래와 같다. (판다스의 행 추가 기능)

기존 pandas 버전에서는 데이터를 추가할 때 append() 메서드를 주로 사용했다. 하지만 pandas 버전이 업데이트되면서, append() 메서드가 더 이상 사용되지 않고 concat() 메서드로 대체되었다. 따라서 새로운 버전에서는 append()를 사용할 수 없으며, 이를 사용하면 오류가 발생할 수 있다.
- 이전 버전 (pandas 1.x): append() 메서드를 사용하여 데이터를 추가함.
- 최신 버전 (pandas 2.0 이후): append()가 삭제되었으며, 데이터를 추가할 때 concat() 메서드를 사용해야 함.
import pandas as pd
# 초기 데이터프레임 생성 (100개의 행이 있다고 가정)
data = {'value': range(1, 101)}
df = pd.DataFrame(data)
print("초기 데이터프레임:")
print(df)
# 데이터를 3번 반복해서 총 300개의 데이터를 만들려면
# 'concat'을 사용하여 데이터프레임을 반복해서 결합합니다.
dfs = [df, df, df] # 동일한 데이터프레임을 3번 반복한 리스트로 생성
df_combined = pd.concat(dfs, ignore_index=True)
# 결과 출력
print("\n추가된 데이터프레임 (총 300개 행):")
print(df_combined)1) 초기 데이터프레임 생성
- data 딕셔너리를 사용해 1부터 100까지의 값을 가진 데이터프레임을 생성.
2) 데이터프레임 병합
- 동일한 데이터프레임을 3번 반복한 리스트를 생성 (dfs).
- pd.concat를 사용해 이를 하나의 데이터프레임으로 결합. ignore_index=True를 통해 새로운 인덱스를 부여.
3) 결과 출력
- 최종 데이터프레임은 300개의 행으로 구성되어 출력된다.
결과물은 동일한 데이터(1~100)가 반복적으로 추가된 데이터프레임이다. ignore_index=True를 사용했기 때문에 최종 데이터프레임의 인덱스는 0부터 299까지 연속적으로 재설정된다.
추가된 데이터프레임 (총 300개 행):
value
0 1
1 2
2 3
...
97 98
98 99
99 100
100 1
101 2
102 3
...
197 98
198 99
199 100
200 1
201 2
...
297 98
298 99
299 100
아래처럼 조각을 내줘야 한다. 아직은 어려울 수도 있다. 프로그래밍 조각내는 스킬이 부족하다면 지피티에 단순한 클래스로 만들어 달라고 물어보자.
네이버 API 연결해서 데이터 분석 (데이터 불러오기, 전처리, EDA, 인사이트 도출)
import requests
import pandas as pd
df = pd.DataFrame()
for x in range(10):
# 네이버 개발자 센터에서 발급받은 클라이언트 ID와 시크릿을 입력합니다.
client_id = 'Your ID'
client_secret = 'Your Password'
query = '직장인'
url = 'https://openapi.naver.com/v1/search/shop.json' # 쇼핑몰
# 요청 헤더에 인증 정보를 추가합니다.
headers = {
'X-Naver-Client-Id': client_id,
'X-Naver-Client-Secret': client_secret
}
params = {
"query": query,
"display": 100
}
# API에 GET 요청을 보냅니다.
response = requests.get(url, headers=headers, params=params)
# 만약 200번이면 응답 구성
if response.status_code == 200:
result = response.json()
tmp = pd.DataFrame(result['items'])
df = pd.concat([df, tmp], ignore_index=True)
else:
print(f"Error: {response.status_code} - {response.text}")
# CSV 파일로 저장
df.to_csv('도시락.csv', index=False, encoding='euc-kr')

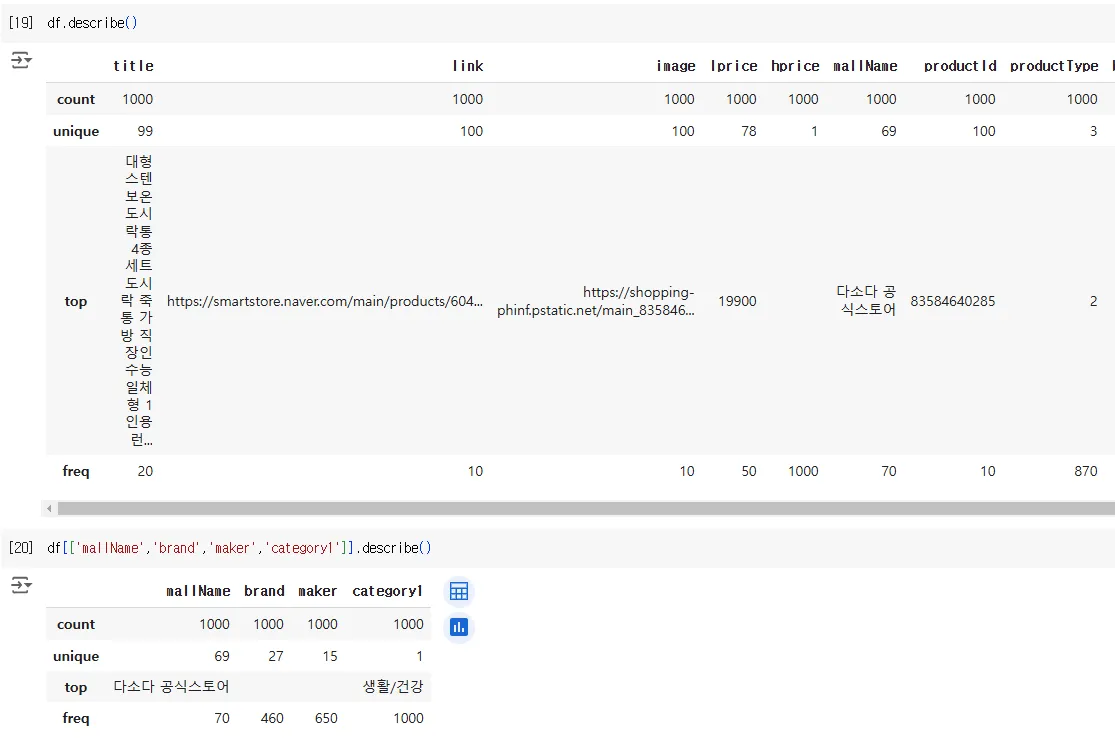
이상한 점 발견.. 데이터 분석이 정말 멋있지 않다. (전처리 이슈)

빈칸인거는 NA라고 나온다. 엑셀에서 데이터 넣을 때 국가,지역 NA라고 넣으면 파이썬으로 넘어가면서 값으로 인지한다. 데이터는 아무것도 안넣거나 NA라는 글자를 쓰면 안된다.
공부하는 자료들은 전처리 이슈들이 없다. 실제자료 받아보면 전처리가 99%이다. 이게 재산이다. 내가 얼마나 전처리를 해봤냐가 내 재산이 된다. PM들은 전처리 이슈를 많이 알아야 한다. 프로그래머들이 전처리를 많이 알고 있을거라고 생각을 안해야 한다. 전처리 이슈에 대한 것은 PM몫이다. 전처리 때문에 일이 하루가 걸릴지 열흘이 걸릴지 모른다.
1) <b>, </b> 삭제하기

2) 결측값 처리하기

GPT에 질문 작성:


데이터분석은 “어떻게 얘를 쓸 수 있을까?” 사고력이 중요하다. 경험치가 중요하다. 데이터라고 하는 숫자값보다 중요한게 경험치이다. 언제 사람들이 보온도시락을 살까? 누가 가지고 다닐까? 부터 고민을 해야한다. 그렇지 않는다면 보온 도시락을 가지고 다니는 사람이 타겟이라면 누구로 할까?
차트작업만 100페이지씩 쓰는데 몇번 하고나면 슬라이드 70-80장씩 만들고하면 그때쯤 되면 보고서가 눈에 들어오기 시작한다. 빨리 써야 내용도 눈에 들어오기 시작한다. 빨리 쓰는 방법론에 대해 고민을 많이 해야한다. 작업량이 쉽게쉽게 되지 않는다.
어차피 창과 방패같다. 올라가는 기술을 걱정할 필요가 없다. 계속 새로운 기술이 나오는데, 인문학자들이 지피티를 못쓰게 하자고 하는데, 그럴거면 아예 핸드폰도 못쓰게 해야한다. 어떻게하면 잘 쓰게 할 것인가? 잘쓰게 하는 방법론을 고민해야한다. 요즘은 IT 윤리교육이 중요하다. 기술력을 어떻게 좋은데 쓸지 고민해야한다. 우리 때는 IT를 배워야 쓰는 시대였지만 저절로 쓴다.
인공지능이 인간을 지배할 수가 없다. 컴퓨터는 이진수만 이해할 수 있고, 제어할 수 있는 것을 심어놓으면 된다. 그걸 걱정할 때가 아니다.
교재 p401
시각화 - 워드클라우드
마이닝 → 데이터마이닝, 텍스트마이닝(단어중요도 & 문장연관도, 이거는 글자를 벡터로 바꾸고 유사도 작업을 해야한다. 문장을 글자화 즉, 명사 단어화, 부사 형태소화하는 모듈이 존재한다. 영어처리모듈 nltk 과 한글처리모듈 konlpy 이 있다.) → 오피니언마이닝
거대한 언어를 처리할 수 있는 것은 LLM이다. 어떤 글자를 벡터화할 것인가가 중요하기 때문에 형태소화시키는 방법론까지 알아야 한다. 고전적인 방법론을 일단 작업을 할 예정이다. 방법은 굉장히 쉽지만 일이 많아서 문제다.
시각화의 목적은 빠르게 의사결정 하는 것이다.
파이썬의 워드클라우드 - 워드클라우드를 보고 고민을 많이 하지 않는다. 워드클라우드의 큰 이슈는 질문에 들어간 질의어는 삭제를 해줘야 한다. 보나마나한 단어는 삭제해 줘야한다.
기업에서 소셜분석한지가 얼마 안됐다. 컨설팅회사도 소셜데이터분석 자체가 없다. 비정형데이터 분석이 없었다. 비정형데이터 분석은 교수님 논문에만 있었다. 정형데이터분석 말고 비정형데이터분석이 꽤있다.

PPT 만들 때 차트옆에 실제 데이터 건수를 보여줘야한다. 그리고 효과적인 워드클라우드 이미지도 추가한다.
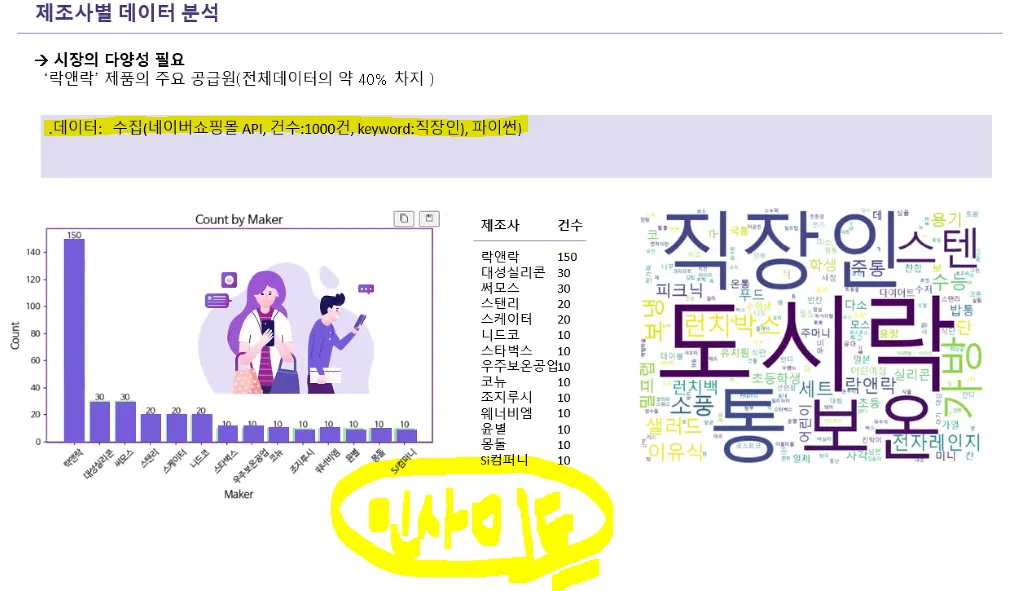
전처리 이슈에 대한 내용도 추가해야하고, 하단에는 도출된 인사이트 설명을 넣어야한다.

강조하고 싶은 것에 색칠하거나 빨간색 네모 넣어준다. 연관이 있다면 넣어주고, 연관이 없으면 빼준다. 사람들이 스텐이나 통, 보온이나 관련이 있고, 전자렌지를 쓸 수 있는 것을 필요로하는지 확인해볼 수 있다. 우리가 분석하는 목적에 따라서 이 키워드가 중요할 수도 있고, 아닐 수도 있다.
→ 이거는 고전적인 데이터 분석이다.
직장인 네이버 쇼핑 API 데이터로 워드클라우드 생성

글꼴 끌어와서 왼쪽에 놓기


gpt 연결해서 코드를 짜면서 워드클라우드 구현했다.

'데이터 AI 인사이트 👩🏻💻 > KPMG 교육' 카테고리의 다른 글
| 비즈니스 애널리틱스 II (1) 랭체인, 판다스 AI 보고서 작성, 생성형 BI, Numpy (0) | 2025.01.26 |
|---|---|
| 비즈니스 애널리틱스 I (3) 텍스트 분할 & 임베딩, 벡터 유사도 분석, 형태소 분석, 네이버 쇼핑몰 데이터 RAG (1) | 2025.01.26 |
| 비즈니스 애널리틱스 I (1) 추천시스템, 파이썬 자료구조, 네이버 API 연결 (1) | 2025.01.26 |
| 디지털 이노베이션 및 빅테크 AI Business 전략 (3) 허깅페이스, 멀티모달, 컴퓨터 비전 (0) | 2024.12.06 |
| 디지털 이노베이션 및 빅테크 AI Business 전략 (2) 오픈 AI 임베딩, RAG, 파싱, requests 모듈, 웹데이터 구조 (4) | 2024.12.06 |



