비즈니스 애널리틱스 II (1) 랭체인, 판다스 AI 보고서 작성, 생성형 BI, Numpy
by Hayley S2025. 1. 26.
(교재) 나도 하는 파이썬 데이터 분석
비즈니스 애널리틱스 II 과정에서는 머신러닝 관련한 기술을 다뤘다.
08. 랭체인_판다스 Ai합쳐서.ipynb (GitHub)
import matplotlib.pyplot as plt
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
!pip install -U langchain-openai
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import skew, kurtosis
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from dotenv import load_dotenv
import os
openai_api_key = 'api키 넣기'
os.environ['OPENAI_API_KEY'] = openai_api_key
# 환경변수 로드(이부분은 별도로 환경변수 작업하)
# #
# load_dotenv()
# api_key = os.getenv("OPENAI_API_KEY")
# if not api_key:
# raise EnvironmentError("OPENAI_API_KEY가 설정되지 않았습니다.")
Part1. 데이터 불러오기
데이터로드
데이터 정보를 이용하여서 gpt에게 데이터 분석에 필요한 작업지시서와, 분석 인사이트를 얻고자함
try:
# 현재 파일 경로 가져오기 (Jupyter Notebook 환경에서는 __file__을 사용할 수 없음)
current_dir = r'C:\Users\Admin\Desktop\study_kpmg\data'
# 엑셀 파일 경로 설정
excel_path = os.path.join(current_dir, '서울시 문화행사 정보.csv')
# 엑셀 파일 읽어오기
df = pd.read_csv(excel_path, engine='python') # openpyxl 엔진 지정
print("데이터 로드 완료")
print(f"데이터 크기: {df.shape}")
# 데이터 확인
display(df.head(1))
except FileNotFoundError:
print("파일을 찾을 수 없습니다. 파일 경로를 확인해주세요.")
except Exception as e:
print(f"오류가 발생했습니다: {str(e)}")
AI를 자동화하고 거창한 것으로 생각하지말고, “AI를 사용해서 데이터를 빠르게 해석해서 1차 회의합시다” 이 정도로 생각하자. 컬럼을 자동으로 생성해주고, 빠르게 데이터를 의사결정에 필요하게 만들어주는데 사용하자고 생각하면 된다.
우리는 결과가 중요한게 아니라 과정이 중요하다.Temp 값이 얼마인지가 중요하다.
# LangChain 설정
llm = ChatOpenAI(temperature=0.7)
prompt = PromptTemplate(
input_variables=["data_summary"],
template="""\
데이터 요약:
{data_summary}
위 데이터를 기반으로 중요한 인사이트를 도출하고, 2024년도서울시문화행사 보고서에 필요한 데이터 결합, 생성, 분석에 대한 작업을 제시해줘
"""
)
chain = LLMChain(llm=llm, prompt=prompt)
myPrompt=df
langchain_response = chain.run(data_summary=myPrompt)
print('-->\n',langchain_response)
-->
1. 각 자치구별로 문화행사의 개최 횟수를 분석하여 문화 행사 활성화 정도를 파악할 수 있습니다. 이를 통해 어떤 자치구에서 문화 행사가 활발히 이루어지고 있는지를 알 수 있습니다.
2. 각 자치구별로 유료와 무료 문화행사의 비율을 분석하여 해당 지역의 문화 행사 참여 형태를 이해할 수 있습니다. 이를 통해 자치구별 문화 소비 성향을 파악할 수 있습니다.
3. 각 자치구별로 문화 행사의 참여 대상을 분석하여 어떤 연령층이 주로 문화 행사에 참여하는지를 파악할 수 있습니다. 이를 통해 해당 자치구의 문화 행사 대상 층을 고려한 행사 기획이 가능합니다.
4. 날짜별로 문화 행사의 개최 횟수를 분석하여 행사 시기에 대한 인사이트를 도출할 수 있습니다. 특정 시기에 문화 행사가 집중적으로 열리는 경향을 파악할 수 있습니다.
5. 기관명을 통해 문화 행사를 주관하는 주체를 파악하여 해당 기관의 활동 범위와 특성을 이해할 수 있습니다. 이를 통해 향후 협력 가능성을 모색할 수 있습니다.
위의 분석을 통해 2024년도 서울시 문화행사 보고서에 필요한 데이터를 결합하여 구체적인 분석 결과와 인사이트를 제시할 수 있습니다.
# LangChain 설정
llm = ChatOpenAI(temperature=0.7)
prompt = PromptTemplate(
input_variables=["data_summary"],
template="""\
데이터 요약:
{data_summary}
위 데이터는 공간복잡도를 계산하여 혼잡도 분산을 위해 사용하는 기초데이터이다.
혼잡도 분석에 필요한 2024년도서울시문화행사.csv 데이터에서 데이터 결합, 생성, 분석에 대한 작업을 최소 10개는 제시해줘
파이썬 코드없이,
"""
)
chain = LLMChain(llm=llm, prompt=prompt)
myPrompt=df
langchain_response = chain.run(data_summary=myPrompt)
print('-->\n',langchain_response)
-->
1. 자치구별로 공연/행사 개최 횟수를 카운트하여 시각화
2. 공연/행사명에서 특정 키워드(예: 뮤지컬)가 포함된 행사만 필터링
3. 날짜_시간 컬럼을 활용하여 월별로 공연/행사 개최 횟수를 카운트하여 시각화
4. 이용대상별로 공연/행사 개최 횟수를 카운트하여 시각화
5. 이용요금 정보를 바탕으로 무료와 유료 공연/행사의 비율을 계산
6. 장소별로 공연/행사 개최 횟수를 카운트하여 시각화
7. 공연/행사의 테마분류별로 개최 횟수를 카운트하여 시각화
8. 경도_X좌표, 위도_Y좌표를 활용하여 지도상에 공연/행사 위치를 표시
9. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하여 평균 공연 기간을 구함
10. 문화포털상세URL을 활용하여 각 공연/행사의 상세 정보 링크를 제공
어떤 데이터를 넣을 것이며, 어떤 프롬포트를 넣을 것인지 템플릿화했다. 그리고 이거를 for구문으로 5번 돌렸다.
# LangChain 설정
result=''
for x in range(5):
# print('-'*100)
llm = ChatOpenAI(temperature=0.7)
prompt = PromptTemplate(
input_variables=["data_summary"],
template="""\
데이터 요약:
{data_summary}
{data_prompt}
"""
)
chain = LLMChain(llm=llm, prompt=prompt)
input_prompt='''위 데이터는 공간복잡도를 계산하여 혼잡도 분산을 위해 사용하는 기초데이터이다.
혼잡도 분석에 필요한 2024년도서울시문화행사.csv 데이터에서 데이터 결합, 생성, 분석에 대한 작업을 최소 10개는 제시해줘
파이썬 코드없이'''
myPrompt=df
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
result+='\n'+langchain_response
result
"\n1. 자치구별로 공연_행사명의 개수를 계산한다.\n2. 자치구별로 유무료 공연의 비율을 계산한다.\n3. 공연_행사명에 '클래식'이 포함된 행사의 개수를 계산한다.\n4. 날짜_시간을 기준으로 2024년에 개최된 공연의 개수를 계산한다.\n5. 이용대상이 '누구나'인 공연의 개수를 계산한다.\n6. 이용요금이 NaN인 공연의 개수를 계산한다.\n7. 이용요금이 있는 공연 중 가장 높은 요금을 확인한다.\n8. 기관명이 '기관'인 공연의 개수를 계산한다.\n9. 출연자정보가 NaN인 공연의 개수를 계산한다.\n10. 테마분류가 NaN인 공연의 개수를 계산한다.\n1. 자치구별로 공연/행사 개수를 집계하여 분포를 확인한다.\n2. 공연/행사명의 문자열 길이를 계산하여 평균값, 최대값, 최소값을 확인한다.\n3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화한다.\n4. 이용대상별로 공연/행사 개수를 집계하여 분포를 확인한다.\n5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인한다.\n6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인한다.\n7. 장소별로 공연/행사 개수를 집계하여 분포를 확인한다.\n8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인한다.\n9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산한다.\n10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시한다.\n1. 자치구별로 공연/행사 개최 횟수를 계산\n2. 자치구별로 유료/무료 행사 개최 비율을 계산\n3. 자치구별로 평균 이용료를 계산\n4. 공연/행사 분류별로 개최 횟수를 계산\n5. 요일별로 공연/행사 개최 횟수를 계산\n6. 월별로 공연/행사 개최 횟수를 계산\n7. 공연/행사 장소별로 개최 횟수를 계산\n8. 공연/행사 시작 시간대별로 개최 횟수를 계산\n9. 공연/행사 종료 시간대별로 개최 횟수를 계산\n10. 공연/행사 기관명별로 개최 횟수를 계산\n1. 각 자치구별로 진행된 공연/행사의 개수를 세어본다.\n2. 각 자치구별로 유료와 무료 공연/행사의 비율을 계산한다.\n3. 날짜_시간 열을 기준으로 2024년에 가장 많은 공연/행사가 진행된 날짜를 찾는다.\n4. 공연/행사명에 '클래식'이 포함된 항목들을 찾아본다.\n5. 이용대상이 '누구나'인 공연/행사 중에서 가장 높은 이용요금을 가진 항목을 찾는다.\n6. 이용요금이 NaN인 항목들을 찾아서 처리한다.\n7. 시작일과 종료일을 활용하여 공연/행사의 기간을 계산한다.\n8. 장소를 기준으로 공연/행사가 진행된 장소의 개수를 세어본다.\n9. 분류별로 공연/행사의 개수를 계산한다.\n10. 공연/행사의 대표이미지를 시각화하여 확인한다.\n1. 자치구별로 공연/행사 개최 횟수를 계산한다.\n2. 날짜_시간 데이터를 기반으로 요일 정보를 추출하여 요일별 공연/행사 개최 횟수를 계산한다.\n3. 이용대상별로 공연/행사 개최 횟수를 계산한다.\n4. 이용요금 정보를 기반으로 무료와 유료 공연/행사 개최 횟수를 계산한다.\n5. 분류별로 공연/행사 개최 횟수를 계산한다.\n6. 장소별로 공연/행사 개최 횟수를 계산한다.\n7. 시작일과 종료일을 기반으로 공연/행사 기간을 계산한다.\n8. 테마분류별로 공연/행사 개최 횟수를 계산한다.\n9. 자치구별로 유무료 공연/행사 개최 횟수를 계산한다.\n10. 기관명별로 공연/행사 개최 횟수를 계산한다."
리스트(list)를 활용하여 데이터를 추가하는 방법과 문자열(str)을 활용하여 데이터를 추가하고 분리(split)하는 방법 비교:
append해서 하나씩 추가해도 좋지만, 텍스트로 들어가도 된다.
a=[]
a.append(’\npython’) ##\n은 구분자이다.
a.append(’\nr’)
a.append(’\nc++’)
[’python’,’r’,’c++’]
append에서는 \n을 안 넣어도 된다. append 말고 또 다른 방법으로는 아래 같은 방법도 있다.
a=’’
a+=’python’
a+r=’r’
a+=’c++’
a=’\npython\nr\nc++’
b=a.split(’\n)
b=[’python’,’r’,’c++’]
→ append는 속도가 느리다. 두번째 방법은 길이에 리밋이 있다. 그래서 상황봐가면서 적절한 방법으로 사용한다. 메모리의 효율성을 따진다. GPT에서 생성된 답변을 append쓸지, 연결해서 쓸지 생각해봐야한다.
result.split('\n')
['',
'1. 자치구별로 공연_행사명의 개수를 계산한다.',
'2. 자치구별로 유무료 공연의 비율을 계산한다.',
"3. 공연_행사명에 '클래식'이 포함된 행사의 개수를 계산한다.",
'4. 날짜_시간을 기준으로 2024년에 개최된 공연의 개수를 계산한다.',
"5. 이용대상이 '누구나'인 공연의 개수를 계산한다.",
'6. 이용요금이 NaN인 공연의 개수를 계산한다.',
'7. 이용요금이 있는 공연 중 가장 높은 요금을 확인한다.',
"8. 기관명이 '기관'인 공연의 개수를 계산한다.",
'9. 출연자정보가 NaN인 공연의 개수를 계산한다.',
'10. 테마분류가 NaN인 공연의 개수를 계산한다.',
'1. 자치구별로 공연/행사 개수를 집계하여 분포를 확인한다.',
'2. 공연/행사명의 문자열 길이를 계산하여 평균값, 최대값, 최소값을 확인한다.',
'3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화한다.',
'4. 이용대상별로 공연/행사 개수를 집계하여 분포를 확인한다.',
'5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인한다.',
'6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인한다.',
'7. 장소별로 공연/행사 개수를 집계하여 분포를 확인한다.',
'8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인한다.',
'9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산한다.',
'10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시한다.',
'1. 자치구별로 공연/행사 개최 횟수를 계산',
'2. 자치구별로 유료/무료 행사 개최 비율을 계산',
'3. 자치구별로 평균 이용료를 계산',
'4. 공연/행사 분류별로 개최 횟수를 계산',
'5. 요일별로 공연/행사 개최 횟수를 계산',
'6. 월별로 공연/행사 개최 횟수를 계산',
'7. 공연/행사 장소별로 개최 횟수를 계산',
'8. 공연/행사 시작 시간대별로 개최 횟수를 계산',
'9. 공연/행사 종료 시간대별로 개최 횟수를 계산',
'10. 공연/행사 기관명별로 개최 횟수를 계산',
'1. 각 자치구별로 진행된 공연/행사의 개수를 세어본다.',
'2. 각 자치구별로 유료와 무료 공연/행사의 비율을 계산한다.',
'3. 날짜_시간 열을 기준으로 2024년에 가장 많은 공연/행사가 진행된 날짜를 찾는다.',
"4. 공연/행사명에 '클래식'이 포함된 항목들을 찾아본다.",
"5. 이용대상이 '누구나'인 공연/행사 중에서 가장 높은 이용요금을 가진 항목을 찾는다.",
'6. 이용요금이 NaN인 항목들을 찾아서 처리한다.',
'7. 시작일과 종료일을 활용하여 공연/행사의 기간을 계산한다.',
'8. 장소를 기준으로 공연/행사가 진행된 장소의 개수를 세어본다.',
'9. 분류별로 공연/행사의 개수를 계산한다.',
'10. 공연/행사의 대표이미지를 시각화하여 확인한다.',
'1. 자치구별로 공연/행사 개최 횟수를 계산한다.',
'2. 날짜_시간 데이터를 기반으로 요일 정보를 추출하여 요일별 공연/행사 개최 횟수를 계산한다.',
'3. 이용대상별로 공연/행사 개최 횟수를 계산한다.',
'4. 이용요금 정보를 기반으로 무료와 유료 공연/행사 개최 횟수를 계산한다.',
'5. 분류별로 공연/행사 개최 횟수를 계산한다.',
'6. 장소별로 공연/행사 개최 횟수를 계산한다.',
'7. 시작일과 종료일을 기반으로 공연/행사 기간을 계산한다.',
'8. 테마분류별로 공연/행사 개최 횟수를 계산한다.',
'9. 자치구별로 유무료 공연/행사 개최 횟수를 계산한다.',
'10. 기관명별로 공연/행사 개최 횟수를 계산한다.']
50개를 질문하면 중복이 있을 수 있기 때문이고, 여기서 중요한 인사이트만 찾으려고 하기 때문에 자료를 쪼갠다.
input_prompt='''위 데이터의 30개의 항목에서 중복을 제거하고,
유사한 항목을 통합한 후 고유한 10개 항목의 분석 작업으로 구성해줘'''
myPrompt=result.split('\n')
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response
'1. 자치구별로 공연/행사 개최 횟수를 계산\n2. 자치구별로 유료/무료 행사 개최 비율을 계산\n3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화\n4. 이용대상별로 공연/행사 개최 횟수를 계산\n5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인\n6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인\n7. 장소별로 공연/행사 개최 횟수를 계산\n8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인\n9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산\n10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시'
이런 부분을 우리가 생각해야 할 부분이다. gpt가 할 수 없는 부분이다.
result2=langchain_response.split('\n')
result2
['1. 자치구별로 공연/행사 개최 횟수를 계산',
'2. 자치구별로 유료/무료 행사 개최 비율을 계산',
'3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화',
'4. 이용대상별로 공연/행사 개최 횟수를 계산',
'5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인',
'6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인',
'7. 장소별로 공연/행사 개최 횟수를 계산',
'8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인',
'9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산',
'10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시']
result 데이터를 가지고, 인사이트를 얻으려고 한다.
input_prompt='''위 데이터의 각 항목당 얻을수 있는 인사이트에 대해 도출해줘'''
myPrompt=result2
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response.split('\n')
['1. 자치구별로 공연/행사 개최 횟수를 계산: 각 자치구가 문화 및 이벤트 활동에 얼마나 많이 참여하고 있는지를 파악할 수 있음.',
'2. 자치구별로 유료/무료 행사 개최 비율을 계산: 각 자치구에서 유료와 무료 행사가 어떻게 분포되어 있는지를 확인할 수 있음.',
'3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화: 시간에 따른 공연/행사의 변화 추이를 쉽게 파악할 수 있음.',
'4. 이용대상별로 공연/행사 개최 횟수를 계산: 공연/행사를 어떤 대상을 대상으로 진행하는지에 대한 정보를 얻을 수 있음.',
'5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인: 공연/행사의 유료와 무료 비율을 파악하여 참가자들이 지불하는 요금에 대한 인사이트를 얻을 수 있음.',
'6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인: 특정 주제나 키워드에 대한 공연/행사가 어떻게 분포되어 있는지를 파악할 수 있음.',
'7. 장소별로 공연/행사 개최 횟수를 계산: 어떤 장소가 가장 많은 공연/행사를 개최하는지를 확인할 수 있음.',
'8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인: 공연/행사의 기간에 대한 통계를 통해 어떤 종류의 이벤트가 얼마나 지속되는지를 파악할 수 있음.',
'9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산: 성인 대상의 평균 이용요금을 파악하여 해당 대상의 이벤트 참여 성향을 이해할 수 있음.',
'10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시: 공연/행사의 지리적 분포를 시각적으로 확인하여 어떤 지역에서 활발하게 문화활동이 이루어지고 있는지를 파악할 수 있음.']
input_prompt='''위 데이터의 각 항목당 얻을수 있는 인사이트에 대해 혼잡도 분산과 연관하여서 도출해줘'''
myPrompt=result2
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response.split('\n')
['1. 자치구별로 공연/행사 개최 횟수를 계산',
' - 인사이트: 어떤 자치구에서 가장 많은 공연/행사가 개최되는지 파악 가능',
' - 혼잡도: 공연/행사가 많이 열리는 자치구는 혼잡도가 높을 수 있음',
'',
'2. 자치구별로 유료/무료 행사 개최 비율을 계산',
' - 인사이트: 각 자치구에서 어떤 유형의 행사가 주로 열리는지 파악 가능',
' - 혼잡도: 유료 행사가 많은 자치구는 혼잡도가 높을 수 있음',
'',
'3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화',
' - 인사이트: 연도별로 공연/행사의 추세를 파악 가능',
' - 혼잡도: 특정 연도에 공연/행사가 집중적으로 열릴 경우 해당 시기의 혼잡도가 높을 수 있음',
'',
'4. 이용대상별로 공연/행사 개최 횟수를 계산',
' - 인사이트: 어떤 이용대상을 대상으로 한 공연/행사가 많이 열리는지 파악 가능',
' - 혼잡도: 특정 이용대상을 대상으로 한 공연/행사가 많을 경우 해당 장소의 혼잡도가 높을 수 있음',
'',
'5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인',
' - 인사이트: 공연/행사의 유료와 무료 비율을 파악하여 이용자들의 경제적 특성을 이해 가능',
' - 혼잡도: 유료 행사가 많은 경우 해당 장소의 혼잡도가 높을 수 있음',
'',
'6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인',
' - 인사이트: 특정 주제나 관심사를 가진 이용자들을 대상으로 한 행사가 어디서 열리는지 파악 가능',
' - 혼잡도: 특정 주제에 관련된 공연/행사가 많으면 해당 장소의 혼잡도가 높을 수 있음',
'',
'7. 장소별로 공연/행사 개최 횟수를 계산',
' - 인사이트: 어떤 장소에서 공연/행사가 가장 많이 열리는지 파악 가능',
' - 혼잡도: 공연/행사가 많이 열리는 장소는 혼잡도가 높을 수 있음',
'',
'8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인',
' - 인사이트: 공연/행사의 기간을 파악하여 이용자들이 얼마나 오래 머무르는지 알 수 있음',
' - 혼잡도: 공연/행사가 긴 장소는 해당 기간 동안 혼잡도가 높을 수 있음',
'',
'9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산',
' - 인사이트: 성인 대상으로 하는 공연/행사의 평균 이용요금을 파악하여 경제력을 이해할 수 있음',
' - 혼잡도: 고가의 이용요금을 가진 공연/행사가 많을 경우 해당 장소의 혼잡도가 높을 수 있음',
'',
'10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시',
' - 인사이트: 공연/행사가 어떤 지역에 집중적으로 열리는지 시각적으로 파악 가능',
' - 혼잡도: 특정 지역에 공연/행사가 집중적으로 열리는 경우 해당 지역의 혼잡도가 높을 수 있음']
['1. 자치구별로 공연/행사 개최 횟수를 계산',
'2. 자치구별로 유료/무료 행사 개최 비율을 계산',
'3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화',
'4. 이용대상별로 공연/행사 개최 횟수를 계산',
'5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인',
'6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인',
'7. 장소별로 공연/행사 개최 횟수를 계산',
'8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인',
'9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산',
'10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시']
# 판다스를 활용하여 자치구별 유무료 개최 횟수를 계산
grouped_df = df.groupby(['자치구']).size().reset_index(name='개최 횟수')
input_prompt='''이 데이터를 분석하여 아래의 질문에 답하세요:
1. 어떤 자치구가 가장 많은 행사를 개최했나요?
2. 이데이터와 연결해야 하는 외부데이터는 어떤 자료가 있을까요?
3. 비율을 계산하여 자치구별로 개최횟수와 비율을 표시해줘
4. 결과를 통해 얻을수 있는 인사이트를 최대한 자세하고 다양하게 '''
myPrompt=grouped_df
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response.split('\n')
['1. 종로구가 가장 많은 행사를 개최했습니다. 총 1371번의 행사를 개최했습니다.',
'2. 이 데이터와 연결할 수 있는 외부 데이터로는 해당 자치구의 인구 통계, 관광객 수, 지역 경제 지표 등이 있을 수 있습니다. 이러한 데이터를 분석하면 행사 개최와 관련된 다양한 요소들을 파악할 수 있을 것입니다.',
'3. 아래는 각 자치구별 행사 개최 횟수와 비율을 나타낸 표입니다.',
'',
'| 자치구 | 행사 개최 횟수 | 비율 |',
'|-------|--------------|------|',
'| 강남구 | 202 | 7.69% |',
'| 강동구 | 89 | 3.39% |',
'| 강북구 | 254 | 9.68% |',
'| 강서구 | 80 | 3.05% |',
'| 관악구 | 99 | 3.77% |',
'| 광진구 | 165 | 6.29% |',
'| 구로구 | 233 | 8.88% |',
'| 금천구 | 48 | 1.83% |',
'| 노원구 | 231 | 8.79% |',
'| 도봉구 | 88 | 3.35% |',
'| 동대문구 | 213 | 8.11% |',
'| 동작구 | 48 | 1.83% |',
'| 마포구 | 282 | 10.74% |',
'| 서대문구 | 40 | 1.52% |',
'| 서초구 | 241 | 9.18% |',
'| 성동구 | 216 | 8.22% |',
'| 성북구 | 157 | 5.98% |',
'| 송파구 | 271 | 10.32% |',
'| 양천구 | 78 | 2.97% |',
'| 영등포구 | 96 | 3.66% |',
'| 용산구 | 135 | 5.14% |',
'| 은평구 | 331 | 12.60% |',
'| 종로구 | 1371 | 52.23% |',
'| 중구 | 471 | 17.95% |',
'| 중랑구 | 65 | 2.48% |',
'',
'4. 위의 데이터를 통해 종로구와 중구가 행사 개최 횟수에서 다른 자치구들과 큰 차이를 보이고 있음을 알 수 있습니다. 이를 통해 종로구와 중구가 문화행사나 축제 등을 활발하게 개최하는 지역임을 알 수 있습니다. 또한, 행사 개최 횟수가 많은 자치구들이 상대적으로 관광객 유치나 지역 경제 활성화에 긍정적인 역할을 할 수 있을 것으로 예상됩니다. 그러므로 향후 지역 발전을 위해 행사 개최에 대한 정책적인 지원이나 활성화가 필요할 것으로 보입니다.']
# 판다스를 활용하여 자치구별 유무료 개최 횟수를 계산
grouped_df = df.groupby(['자치구', '유무료']).size().reset_index(name='개최 횟수')
input_prompt='''이 데이터를 분석하여 아래의 질문에 답하세요:
1. 어떤 자치구가 가장 많은 무료 행사를 개최했나요?
2. 유료 행사가 가장 많은 자치구는 어디인가요?
3. 무료와 유료 행사의 비율을 계산하여 자치구별로 요약해서 데이터프레임으로 표시
4. 결과를 통해 얻을수 있는 인사이트를 최대한 자세하고 다양하게 '''
myPrompt=grouped_df
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response.split('\n')
['1. 종로구가 가장 많은 무료 행사를 개최했습니다. 종로구는 총 734번의 무료 행사를 개최했습니다.',
'',
'2. 유료 행사가 가장 많은 자치구는 강북구입니다. 강북구는 총 145번의 유료 행사를 개최했습니다.',
'',
'3. 무료와 유료 행사의 비율을 계산하여 자치구별로 요약한 데이터프레임은 아래와 같습니다:',
'',
'| 자치구 | 무료 행사 횟수 | 유료 행사 횟수 | 무료/유료 비율 |',
'|--------|--------------|--------------|--------------|',
'| 강남구 | 127 | 75 | 1.69 |',
'| 강동구 | 23 | 66 | 0.35 |',
'| 강북구 | 109 | 145 | 0.75 |',
'| 강서구 | 35 | 45 | 0.78 |',
'| 관악구 | 73 | 26 | 2.81 |',
'| 광진구 | 81 | 84 | 0.96 |',
'| 구로구 | 111 | 122 | 0.91 |',
'| 금천구 | 36 | 12 | 3.00 |',
'| 노원구 | 181 | 50 | 3.62 |',
'| 도봉구 | 80 | 8 | 10.00 |',
'| 동대문구 | 168 | 45 | 3.73 |',
'| 동작구 | 47 | 1 | 47.00 |',
'| 마포구 | 179 | 103 | 1.74 |',
'| 서대문구 | 32 | 8 | 4.00 |',
'| 서초구 | 113 | 128 | 0.88 |',
'| 성동구 | 159 | 57 | 2.79 |',
'| 성북구 | 108 | 49 | 2.20 |',
'| 송파구 | 225 | 46 | 4.89 |',
'| 양천구 | 61 | 17 | 3.59 |',
'| 영등포구 | 65 | 31 | 2.10 |',
'| 용산구 | 119 | 16 | 7.44 |',
'| 은평구 | 303 | 28 | 10.82 |',
'| 종로구 | 734 | 637 | 1.15 |',
'| 중구 | 361 | 110 | 3.28 |',
'| 중랑구 | 40 | 25 | 1.60 |',
'',
'4. 위의 데이터를 통해, 각 자치구의 무료와 유료 행사 개최 비율을 확인할 수 있습니다. 도봉구와 은평구가 무료 행사를 많이 개최한 반면, 동작구는 유료 행사를 거의 개최하지 않았습니다. 이러한 데이터를 통해 각 자치구의 문화/이벤트 활동에 대한 특징을 파악할 수 있고, 향후 이벤트 기획이나 자치구별 예산 배분에 참고할 수 있습니다. 또한 무료 행사를 많이 개최하는 자치구는 주민들에게 문화 활동을 제공하는데 더 많은 노력을 기울일 필요가 있을 것으로 보입니다.']
df넣고 할 수 있는 모든걸 해보라고 gpt에 질문하면 잘한다.1번부터 4번까지는 우리가 직접 입력한다.
판다스 데이터 프레임에 해당하는 작업을 할 때, template화해서 어떤 데이터를 넣고, 프롬프트를 넣을테니 이거를 해줘라고 템플릿화해서 작업한다.
그리고 판다스가 제공하는 AI 기능을 넣어서 작업하면 gpt보다는 대답을 잘해준다. 그런데 아주 잘되거나 하지는 않는다.
여기에 들어가서 관련 내용 확인하자. Generatvie BI라는 생성형 BI 내용이다. 비전문가들이 데이터에 기반한 자동화된 분석을 자유롭게 할 수 있다. Generative BI Tool로 gpt api 직접 코딩으로 작업했고, 판다스에서 제공하는 gpt와 AI(최신)가 있다.
Amazon Q라는 업무용으로 설계된 생성형 AI 어시스턴트가 있다. Power BI도 비슷하게 잘되어있다. 사용자가 AWS 사용하는데 어떤 DB에서 어떤 인사이트를 찾을 수 있는지 확인할 수 있다는 것이다.
만약 회사에서 전사적으로 적용해야 한다면 어떤 기능을 필요로 하는지 보고, 회사에서 가지고 있는 데이터 셋과 회사 직원들의 수준을 고려해서 결정한다. 수준에 따라서 교육을 할지, 아니면 아예 템플릿 샘플링을 해놓고 쓸지, AI 어시스턴트 작업만 하는 직원을 뽑을지, 어떤것이 효율적인지 확인한다. 항상 비용이 많은 것을 채택하지 않는다.
Generatvie BI에서 pandas가 데이터 분석 프레임 툴을 많이 제공하기 때문에 판다스가 앞서나가고 있다. pandas ai가 나중에 나온 것이다. 주피터 노트북에서 gpt를 생성하고, open ai 키를 설정하고, csv를 받아오면 대륙별 관련된 세일즈를 확인할 수 있다. 세일즈 값을 가지고 얘기를 해달라고 한다. df.ask라고 물어보면 시각화 그래프가 나온다. 해보면 데이터가 잘 안나오는게 많다. 그래서 그 다음 나온게 pandas ai가 나왔다.
pandas ai는 sql 연결 커넥터도 제공하고, 다양한 LLM 적용이 가능해졌다. pandas ai를 권장한다.
#####################################
# pandas_gpt를 이용한 작업
# https://normalstory.tistory.com/entry/Pandas-AI-%ED%8C%90%EB%8B%A4%EC%8A%A4AI-with-LLM-Agent-OpenAI-MySQL
%pip install -q pandasai
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
df_Ai = SmartDataframe(df, config={"llm": llm})
df_Ai
Note: you may need to restart the kernel to use updated packages.
<pandasai.smart_dataframe.SmartDataframe at 0x184d89f3e80>
result2
['1. 자치구별로 공연/행사 개최 횟수를 계산',
'2. 자치구별로 유료/무료 행사 개최 비율을 계산',
'3. 날짜_시간을 기준으로 연도별 공연/행사 개수를 시계열 그래프로 시각화',
'4. 이용대상별로 공연/행사 개최 횟수를 계산',
'5. 이용요금의 결측치를 처리하고, 유료와 무료의 비율을 확인',
'6. 공연/행사명에 특정 단어가 포함된 행을 필터링하여 확인',
'7. 장소별로 공연/행사 개최 횟수를 계산',
'8. 시작일과 종료일을 활용하여 공연/행사 기간을 계산하고, 평균값을 확인',
'9. 이용대상과 이용요금을 결합하여 성인 대상의 평균 이용요금을 계산',
'10. 경도_X좌표와 위도_Y좌표를 이용하여 지도에 공연/행사 위치를 표시']
# 에러나오면 다시 실행해봄
###############################3
## 판다스_gpt
# https://calmmimiforest.tistory.com/125
pandasMsg=result2[3] # 0번부터 시작함으로 원하는 질문에서 번호-1
print('\n-->',pandasMsg)
tmp=df_Ai.chat(pandasMsg)
tmp
##########################
## 일반 gpt(랭체인) 연결
###########################
input_prompt='''이 데이터를 분석하여 아래의 질문에 답하세요:
결과를 통해 얻을수 있는 인사이트를 최대한 자세하고 다양하게 '''
myPrompt=tmp
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response.split('\n')
['1. 이벤트 개최 횟수가 가장 많은 이용대상은 누구인가?',
'- 이벤트 개최 횟수가 가장 많은 이용대상은 "누구나"이다. 이용대상이 가장 넓은 범위를 가지고 있기 때문에 이벤트에 참여하는 사람들이 많을 것으로 추정할 수 있다.',
'',
'2. 이벤트 개최 횟수가 가장 적은 이용대상은 무엇인가?',
'- 이벤트 개최 횟수가 가장 적은 이용대상은 "8세이상관람가[미취학아동입장불가]"이다. 이용 대상이나 제한 사항이 있는 경우에는 참여자 수가 적을 수 있다.',
'',
'3. 이용대상별 이벤트 개최 횟수의 분포는 어떠한가?',
'- 대부분의 이용대상이 100회 이하의 이벤트를 개최했으며, 상위 소수의 이용대상이 100회 이상의 이벤트를 개최한 것으로 나타난다. 이용대상에 따라 이벤트 개최 횟수가 크게 다를 수 있다.',
'',
'4. 특정 연령대가 많이 참여하는 이벤트는 무엇인가?',
'- 초등학생 이상이라는 이용대상이 109회의 이벤트를 개최한 것으로 나타난다. 이용대상별로 이벤트 참여자 수가 다를 수 있기 때문에 특정 연령대가 많이 참여하는 이벤트가 있을 수 있다.',
'',
'5. 성인을 대상으로 하는 이벤트가 다른 이용대상을 대상으로 하는 이벤트보다 어떤 특징을 가지고 있는가?',
'- 성인을 대상으로 하는 이벤트의 개최 횟수가 183회로 비교적 많은 편이다. 성인을 대상으로 하는 이벤트는 다른 연령대나 대상을 대상으로 하는 이벤트보다 참여자가 많을 가능성이 있으며, 성인들에게 인기 있는 이벤트가 많이 개최되었을 수도 있다.']
##########
### 판다스_gpt
# https://calmmimiforest.tistory.com/125
plt.figure(figsize=(10,20))
pandasMsg=result2[3] +'결과에 대한 가로 막대그래프를 그려줘, 건수가 10건이상인 자료만'
print('\n-->',pandasMsg)
tmp=df_Ai.chat(pandasMsg)
tmp
##########################
## 일반 gpt(랭체인) 연결
###########################
input_prompt=f'''{pandasMsg}의 결과를 분석하고, 이 자료를 통해 얻을수 있는 인사이트를 최대한 자세하고 다양하게 '''
myPrompt=tmp
langchain_response = chain.run(data_summary=myPrompt, data_prompt=input_prompt)
langchain_response.split('\n')
--> 4. 이용대상별로 공연/행사 개최 횟수를 계산결과에 대한 가로 막대그래프를 그려줘, 건수가 10건이상인 자료만
['분석해보겠습니다. 먼저, 이용대상별로 공연/행사 개최 횟수를 계산하여 가로 막대그래프를 그려보겠습니다. 분석 결과 건수가 10건 이상인 자료만을 고려하여 분석을 진행하겠습니다.',
'',
'분석 결과를 통해 얻을 수 있는 인사이트는 다음과 같습니다:',
'',
'1. 인사이트 1: 가장 많은 공연/행사가 개최된 이용대상은 무엇인가?',
' - 가로 막대그래프를 통해 가장 많은 공연/행사가 개최된 이용대상을 확인할 수 있습니다. 이를 통해 어떤 이용대상이 가장 많은 관심을 받았는지 파악할 수 있습니다.',
'',
'2. 인사이트 2: 건수가 10건 이상인 자료들 간의 비교 분석 결과는 무엇인가?',
' - 건수가 10건 이상인 자료들을 비교하여 어떤 이용대상이 가장 활발하게 공연/행사를 개최했는지, 그 이유는 무엇인지 등을 분석할 수 있습니다.',
'',
'3. 인사이트 3: 이용대상별로 공연/행사 개최 횟수의 추이는 어떤 모습인가?',
' - 과거부터 현재까지 이용대상별 공연/행사 개최 횟수의 추이를 분석하여 특정 이용대상의 활동이 증가하거나 감소하는 추세를 발견할 수 있습니다.',
'',
'4. 인사이트 4: 공연/행사 개최 횟수와 관련된 다른 변수들과의 상관관계는 무엇인가?',
' - 공연/행사 개최 횟수와 관련된 다른 변수들(예: 날씨, 계절, 지역 등)과의 상관관계를 분석하여 공연/행사가 활발히 이루어지는 요인을 발견할 수 있습니다.',
'',
'이와 같이 다양한 인사이트를 분석하여 공연/행사 개최에 대한 효율적인 전략을 수립할 수 있을 것입니다.']
<Figure size 1000x2000 with 0 Axes>
생성형 BI란?
기업들은 리턴값이 확실하고, 명확해야 투자를 하는데, 회사에서는 인공지능을 이용해서 무언가를 분석하는 일을 잘 하지 않는다. 네이버와 같은 서비스에서는 인공지능을 사용해서 서비스를 제공하고 있는데, 대기업들은 이미 공장자동화가 어느정도 다 만들어져 있어서 이미 라인들이 잘되어있는데 다 없애고 인공지능을 넣지 못한다. 그렇기 때문에 인공지능이 활발하게 들어가고 있는 곳은 열악한 중소기업들이다. 인공지능은 내부적으로 대기업들은 하고 있는 파트는 물류에서의 로봇들이 물건을 이동하는 것들은 하고 있지만, 중소기업에서는 아주 열악한 곳들이 물건들이 팔이 되어서 어떤 물건인지 확인하고 자리에 이동하는 것을 한다.
대기업들이 할 수 밖에 없는 내용은 생성형 BI이고, 이게 인공지능이다. 필요한 부분을 발췌를 하고 문서의 내용을 요약해준다. 지금은 기업들이 본인들이 가지고 있는 데이터셋을 가지고 자동화된 상담원이나 문서요약, 문서 내에서의 질의응답 정도는 우리도 하는데 대기업들도 이쪽을 할 수 있다. RAG 파트는 일주일만에 끝나기도 하고, 에러가 나기도 하지만, 전산팀들이 정답이 없는 부분을 싫어해서 RAG같은거 싫어한다. 그래도 할 수 밖에 없는 현실이다. 고객응답센터/컨택센터/CS센터에서 하는 것을 잘 봐야 한다. 생성형 BI라고 하는 부분에 대해서 2024년 하반기에 나오는 리포트들을 잘봐야 한다. 다만, 생성형 BI 툴들이 아주 많을 것이다. BI 솔루션들이다. 우리나라 솔루션도 있고, 아마존 솔루션도 있고, 태블로도 있고, Power BI는 진작에 있었다. BI 관련 툴들에 대해서도 확인을 해봐야 한다. 아직 업무적으로 다 가져다 못 쓰니까 아마존 클라우드 기반에서 작업을 하려고 한다. 우리가 확인할 때는 클라우드 기반 생성형 BI 툴을 검색해서 찾는다. 찾을 때는 Azure/AWS 생성형 BI툴이라고 검색해서 보고, 자료볼 때는 2024년 하반기 이후에 나온 자료만 보자.
플랫폼 사용할 때는 확실한 목적성을 가져야 한다. 이쪽 트렌드가 굉장히 빨리 변하고 있다. 우리를 채용한다면 회사에서는 바뀌는 트렌드에 따라서 우리가 어떤 업무를 할 수 있는지 너네가 말해달라는 식으로 바라고 있다. 아예 모르겠으니까. 이런 트렌드를 보기 위한 사이트로 현재 시장에 나와있는 툴들 회사 사이트를 확인할 수 있다. BI 관련 플랫폼을 잘 찾아보자. 비즈니스 인사이트를 찾는 BI, 여기에 쓰이는 생성형 AI다.
오늘은 Numpy에 대해서 배울 것이다. 넘파이는 판다스와 다른 것이 리스트로 구성되어있고, 열과 행을 인덱싱하는 것부터 해서 계산하는 방법론, 계산되는 방법으로 브로드캐스트를 사용할 것이고, dtype을 사용할 것이다. 인공신경망쪽에서 dtype 알아야 한다.
선생님이 pdf자료를 만들어주면 gpt를 잘 쓰고 있으니까 혼자 공부할 때 자료를 넣고 저 작업에 대해서 이해할 수 있게끔 설명해주라고 입력할 것이지만, gpt는 장수가 많으면 더더욱 설명을 못한다. 요약은 꽤잘한다. 하지만 설명을 해달라고 하면 통으로 설명을 잘 못한다. 귀찮더라도 한장씩 낱장으로 쪼개서 설명해달라고 하면 설명을 더 잘해준다. 한장씩 업로드해서 설명해달라고 입력한다.
이거 깔아놓으면 지피티 내용 pdf로 저장할 수 있다.
생성형 BI 관련 도보자료
류진수 LG CNS D&A사업부 총괄 마이스터
https://zdnet.co.kr/
[기고] 기업 데이터 분석의 새로운 패러다임, 생성형 BI (입력 :2024/09/13 10:29)
그야말로 AI열풍이다. 기업에서는 업무 전반에 인공지능(AI) 특히, 대규모 언어모델(LLM)을 적용하거나 새로운 비즈니스 기회를 창출하는 시도가 활발하게 이루어지고 있다.
LLM은 언어 모델이기 때문에 주로 비정형 텍스트 문서를 기반으로 AI 활용을 모색하고 있다. LLM의 단점을 보완하기 위해 검색 증강 생성(RAG) 아키텍처를 적용하는 경우도 많다.
다만, 기업의 중요한 정보는 비정형(unstructured) 문서에만 존재하는 것이 아니라, 관계형 데이터베이스(RDB) 같은 데이터 저장소에 정형(structured) 형태로도 존재한다. RDB 데이터의 LLM 적용을 위해서 RDB 데이터를 문서형태로 변환하는 것은 비효율적이다.
RDB 데이터는 SQL을 통해 질의하고 결과를 얻는 것이 적절하므로, LLM이 SQL을 생성하도록 하는 것이 바람직하다. 이 과정은 자연어 기반 질의(NL2SQL) 영역에 속하며, LLM이 자연어 질의를 SQL로 변환할 수 있다. LLM은 자연어 질의에 대한 답변을 비롯해 SQL 작성에도 비교적 높은 수준의 성능을 보인다.
다만, LLM은 조직의 내부 DB 정보를 학습하지 않았으므로 RAG 방식으로 기업 내 DB 정보를 LLM 프롬프트에 질의와 함께 전달해 주면, 비교적 정확한 SQL을 생성할 수 있다.
RDB에 데이터를 저장하고 분석하는 일은 전통적인 비즈니스 인텔리전스(BI) 영역에 속한다. 데이터 분석을 목적으로 한 NL2SQL은 BI 영역에 생성형AI를 적용한 것이므로 '생성형 BI'라 부를 수 있다. 글로벌 리서치 기관인 가트너에서도 생성형 BI라는 용어를 사용하기 시작했으며, 비정형 텍스트를 대상으로 생성형AI가 활발히 적용된 만큼, 정형 데이터를 대상으로 한 생성형 BI 영역도 급속도로 성장할 것으로 예상된다.
하지만 LLM이 생성하는 SQL이 항상 정확한 것은 아니다. 단순한 DB 모델에서는 LLM의 정확도가 높지만, 복잡한 DB 모델에서는 성능이 떨어질 수 있다. 정확도를 높이기 위해 DB 정보에 대한 설명을 풍부하게 만들어주면 성능이 향상될 수 있으나, 여전히 100% 만족하기는 어렵다.
그 이유는 기업의 복잡한 업무가 DB 테이블 설계에 반영되어 있을 뿐만 아니라, DB 설계자의 설계 스타일도 반영되기 때문이다. 이러한 정보를 모두 서술하기도 어렵고, LLM에 전달해도 이해하지 못해 잘못된 SQL을 생성할 가능성이 크다.
또 다른 문제점은 BI 데이터 분석이 주로 수치화된 정보를 다룬다는 점이다. 예를 들어, 판매수량, 판매금액, 생산수량, 불량수량 등을 집계하는 경우가 많은데, 잘못 생성된 SQL의 결과값이 정답 SQL의 결과값과 조금만 다르다면, 예를 들어 연간 매출액이 10조인데 9.9조나 10.1조의 결과가 나왔다면, 사용자가 이를 오답으로 인지하기 어렵다.
텍스트 문서를 기반으로 한 생성형 AI의 답변이 거짓일 경우, 예를 들어 "세종대왕이 아이패드를 던졌다"는 식의 거짓말은 문장의 특성상 사용자가 쉽게 알아차릴 수 있지만, 숫자로 된 답변은 큰 차이가 아니라면 잘못된 결과임을 인지하기 어렵다.
이러한 Gen BI의 한계를 극복하는 방법 중 하나는 온라인 분석 처리(OLAP)를 활용하는 것이다. OLAP은 SQL을 모르는 사용자도 DB 데이터를 분석할 수 있게 해주는 기술이다.
사용자가 OLAP솔루션에서 OLAP리포트를 작성하고 실행 버튼을 누르면, OLAP엔진이 SQL을 자동 생성해주고 실행 결과를 리포트에 반환해준다. 마치 엑셀의 피봇테이블 기능으로 엑셀의 데이터를 분석하는 것과 유사하다.
OLAP이 쿼리 생성자로서의 역할을 수행하는 셈이다. OLAP은 수십 년에 걸쳐 상용화된 기술로, OLAP의 쿼리는 항상 안전하고 정확하다. OLAP 메타데이터를 설정할 때 비즈니스 메타데이터와 기술 메타데이터의 매핑 및 테이블 간의 조인 관계를 미리 설정하기 때문에, 설정되지 않은 조합의 SQL은 생성되지 않는다.
OLAP 기반의 Gen BI에서는 LLM이 OLAP 리포트 항목을 선택할 수 있도록, RAG 방식에서 DB 정보 대신 OLAP 메타 정보를 전달하면 된다. 이후 LLM이 OLAP 리포트를 생성하면, OLAP 엔진을 통해 정확한 SQL을 생성하고 실행할 수 있다.
OLAP 기반 생성형 BI의 또 다른 장점은 NL2SQL 방식의 Gen BI보다 오류 식별이 용이하다는 점이다. 질의에서 바로 SQL이 생성되는 것이 아니라, 중간 단계에서 OLAP 리포트 항목(관점, 측정값, 필터 조건 등)이 만들어지므로, 사용자가 이를 보고 LLM이 올바른 답을 도출했는지 쉽게 검증할 수 있다.
많은 OLAP 기반 BI 솔루션과 분석 솔루션들이 Gen BI 기능과 서비스를 출시하고 있다. 아직 Gen BI는 초기 단계이지만, 정확도를 높이기 위한 RAG 적용이나 외부 LLM 활용에 따른 데이터 보안 문제 등이 점차 개선될 것으로 보인다.
예를 들어 마이크로스트레티지와 같은 OLAP 기반 BI 솔루션 제공업체들은 기존 BI의 장점에 AI를 결합한 솔루션을 제공하고 있다.
NL2SQL 기반의 생성형 BI도 SQL을 아는 개발자나 분석가의 생산성을 높이는 초도 Query 작성용으로 활용한다면 가치를 발휘할 것이다. 그러나 SQL을 모르는 일반 사용자에게는 OLAP 기반의 생성형 BI가 더 유리할 것이다. 언제까지? 아마도 LLM이 DB 설계자의 성향까지 극복해 정확한 NL2SQL을 생성할 때까지일 것이다. 챗GPT의 등장과 빠른 업그레이드처럼, 그 시기는 예상보다 빨리 올 수도 있다.
출처: https://zdnet.co.kr/view/?no=20240913102145
pdf 불러와서 설명시키고 테스트문제와 코드문제, 서술형문제 생성해내기 실습
Numpy 모듈
넘파이 모듈은 파이썬 중에서 통계 관련기능을 구현, 업데이트 되는 부분을 알기 위해서는 넘파이 가이드를 읽는 것이 원칙이다.
공식문서 확인해보기
인공지능 파트로 넘어가고 싶으면 넘파이는 잘해야한다. 머신러닝, 딥러닝 쪽은 혼자 공부하기 한계가 있다.
넘파이는 반드시 매뉴얼 공부하고 쓰는 것을 권장한다. 넘파이는 잘못쓰면 넘파이를 넘파이답게 잘 못쓴다.
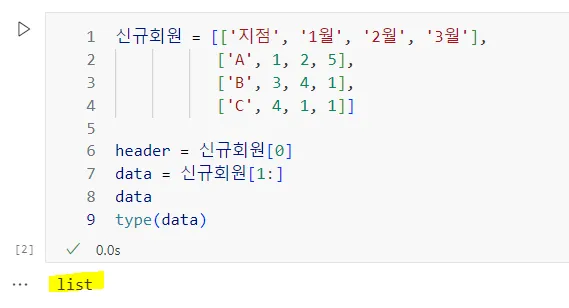
type(data)을 사용해서 타입을 먼저 확인한다.array하려면 가로세로 갯수가 맞춰져야 에러없이 출력된다.
기본적으로 넘파이는 숫자데이터가 들어왔을 때 쓰려는 것이다. 기본적으로 숫자데이터를 빠른 처리속도로 처리하려고 쓰는 것이다. 그렇다보니 칼럼 A,B,C는 필요없다. 숫자만 필요하다고 할때, 0번 1번 2번 인덱싱이 다 필요하다는 뜻으로 print(data)라고 하고, data.shape이라고 출력해서 보면 (3,4)라고 나온다.
(2,5,3) 이렇게 하면 [1,1,1] 3개 들어간게 5개가 있고, 이렇게 5개가 있는게 2개가 있다는 뜻이다.
데이터의 집합체를 array 구조라고 한다. array만 전문적으로 처리하는 넘파이가 있다.
인공신경망과 머신러닝에서 필요한 것만 맞춰서 공부할 수 있는 자료가 별로 없어서 강의를 잘 들어야겠다.
A,B,C는 빼고 싶어할 때, 인덱싱을 한다. data[:, 1:]은 특정 열을 제외하고 나머지 데이터를 선택하는 numpy 인덱싱 방식이다.
리스트(list)는 기본적으로 2차원 배열처럼 동작하지 않으므로, numpy의 인덱싱 방식을 사용할 수 없다. loc는 속도가 엄청 느리다. loc는 데이터프레임에서 라벨을 기반으로 데이터에 접근하기 때문에, numpy에 비해 상대적으로 느릴 수 있다는 것이다.
astype은 타입을 변경시켜준다. uint8 언사인이라는 뜻으로 데이터값이 숫자로 바뀐다.
언사인이기때문에 부호값을 안받는다. 부호없는 int8(정수) 소수점없는 정수 8개 비트로 표현하겠다는 것이다. 커봐야 256밖에 표현할 수 없게 만들었다. 이거는 컬러 표현할 때 쓰인다. 그 외의 값은 의미가 없다는 것이다. 나중에 딥러닝 들어갔을 때 이미지 깨질 때 쓰일 수 있다. 딥러닝에서 이미지 자료를 볼 때가 많고, 출력을 해야하는데, 값이 더하기 빼기가 잘못되면 이미지가 깨진다.
넘파이의 장점은 브로드캐스트가 있다. 한번에 널리 전파하는 것이다. 계산이 편해진다.
인원수가 있는데 100명을 다 증원한다고 하면, 판다스에서 한다고 하면 A 필드 100, B 필드 100, C 필드 100이라고 넣을 때 전체행 : 그리고 0번째 열에만 100을 더한다고 하면 아래와 같이 출력된다.
Max값은 255다.
이미지를 처리한다고 하면 맥스값을 255라고 해놔야 흰색으로 바뀐다는 것이다. 값이 0에서 255로 계속 넘어가고 있다는 것이다. 255를 일정량 넘어가면 다시 0값으로 떨어져서 검정색이 안되기 위해서 밝은 색이 되게 만든다. 사진이 안나오는 이유는 언사인 이미지 unit8에 걸려야하는데 안걸려서 이미지 파일을 인식 못한 것이고, 이런 상황이 딥러닝에서 자주 발생한다.
브로드캐스트의 뜻은 행과 열의 부분을 찝어주게 되면 알아서 해당 행과 열에만 적용되어 계산이 된다.
numpy는 if 안쓴다. np.where라는 걸로 쓴다.
re.shape을 한번 더 보자. 아래는 1차원 array다.
데이터는 나이만 들어갈지, 나이말고 다른게 들어갈지 모른다. 데이터가 age에만 들어갈지 어디에 들어갈지 모른다.
행과 열의 구조는 변경할 수 있다.
데이터가 작업을 하다보면 아래와 같은 상황을 맞닥뜨릴 수 있다.
인공지능에서는 reshape이 필수다. 인공신경망에서는 한줄로 묶어진 데이터들로 많이 이루어져있다.
데이터의 구조는 언제든지 변경가능하다. 가로와 세로의 형태가 행렬구조로 있기때문에 언제든지 변경할 수 있는 것이 장점이다. 판다스보다 낫다. 파이썬 속도가 많이 떨어진다. 판다스는 빠르게 이상치를 찾지 못한다. 시그널/신호 데이터라고 하면 넘파이가 필수다.