수업 진도
9시~10시: 넘파이 마무리(행열곱셈, 회귀방정식의 기본식 이해)
10시~11시: 군집분석(k-means) 기초: 넘파이 인덱스를 알야야 볼수 있어요.
11시~1시: 고객클러스터링 파이썬
2시~4시: 상관계수, 클러스터링, 인사이트 도출
[클러스터링기초] https://github.com/codestates/ds-blog/issues/126
[실습기초_고객분류세그멘테이션, 쉽게나옴]
https://www.kaggle.com/code/kushal1996/customer-segmentation-k-means-analysis
[읽기]
https://brunch.co.kr/@kkokkodaec/32
[수학적으로 해석]
https://gem763.github.io/machine%20learning/K-means-clustering.html
K-means clustering
데이터에 대한 사전정보가 전혀 없는 상태에서, 해당 데이터들을 몇 개의 그룹으로 나누고 싶을 때가 있다. 이를 클러스터링 문제라고 한다. 머신러닝에서 클러스터링은 전형적인 비지도학습 (U
gem763.github.io
Customer Segmentation (K-Means) | Analysis
Explore and run machine learning code with Kaggle Notebooks | Using data from Mall Customer Segmentation Data
www.kaggle.com
이어서 넘파이 수업

[ , , ] 이런 것도 있고, [:,:] 이것도 된다. 여러가지 형태 알아야 한다.
브로드캐스트

여기서 dtype이 다르면 오류가 난다. type들 잘봐야한다. 연산은 같은 type끼리만 가능하다.

조건문 나중에 많이 사용하게 될 것이다.
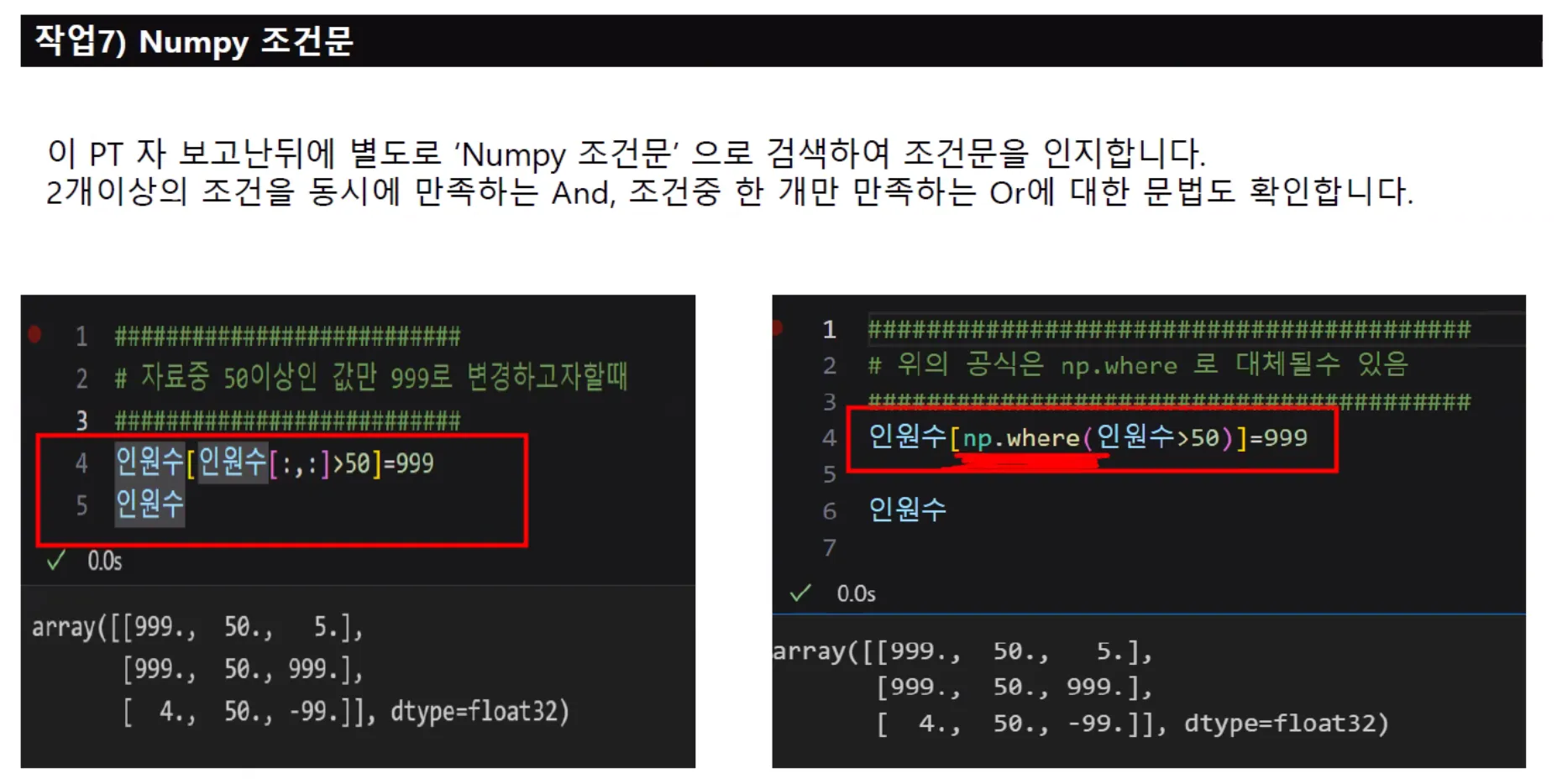
속도가 다르다. 넘파이가 자체적으로 가진 함수를 사용하여 계산하여 C기반이라서 속도가 다르다.


조건 걸어서 연산하고 싶으면 다른 프로그래밍은 아래처럼 써야하지만, 넘파이는 npwhere 를 쓴다.
인공신경망/코딩 쪽으로 가고 싶다면 특히 이미지 처리를 하고싶다면 넘파이쪽 잘 봐야 한다. 자율주행 관련 회사는 이미지 처리하는 회사다. 이미지를 불러와서 어떻게 처리하는가?는 다 넘파이 쓴다. 넘파이를 잘 쓰는 것이 관건이고, 넘파이를 잘한다는 것은 C 잘한다고 본다.


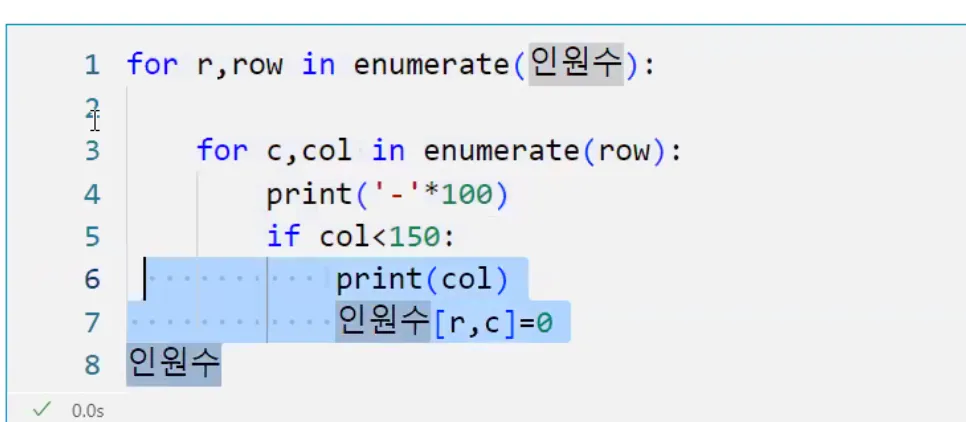
덧셈을 할때, 위로 덧셈할지 아래로 덧셈할지 결정한다.

w는 웨이트, 예측값 곱하는 식을 만든다.


인공신경은 예측값을 위처럼 계산을 막 하면서 뭐가 제일 가까운지 찾아내는 거다.
머신러닝은 내가 고른 모델, 회귀모델/랜덤포레스트 모델 안에 공식이 다 있다. 공식에 의하여서 예측하는 값이 나오는 것이다.
실제y가 나오려면 +오차를 해야 y값이다.


선형선 linear 가 나온다. 선형계수
프로그램 행렬에서는 어떻게 처리하는 건가? 지금 예제 자료 인원수가 있다. weight값을 보려고 한다면 전체 데이터 행에 x1해주면 값이 그대로 나온다. 두번째로는 x2해주고, 세번째로는 x0을 해준다.

위에거를 다 더해준다.

행렬의 내적곱이라고 해서 곱하고 더하기를 동시에 하는 것이다. 이거는 파이썬과 상관없이 행렬은 내적곱을 하려면 무조건 아래 처럼 같아야 한다.


곱하고 더하면 w 결과값 나온다.

vstack과 hstake: 행에 들어갈지, 열에 들어갈지

https://www.ebssw.kr/info/intrcn/infoTchmtrHeaderView.do?tabType=AI
이솦 | EBS 소프트웨어·인공지능 교육
이솦 | EBS 소프트웨어·인공지능 교육
www.ebssw.kr
지금 초중고에서 배우는 AI 수준 확인함. 생각보다 난이도 있음.
블록형코딩으로 배운다고 함.

이미 모델에 있는 거에 집어 넣는 거를 한다.
실제로 회사에 들어가면 직접 모델을 만들기도 하지만, 구글 클라우드 플랫폼(GCP), 마이크로소프트 Azrue 클라우드 플랫폼에 가보면 이미 만들어질 확률이 있다. 드래그앤드롭으로 가능하다.
이미 졸업한 애들은 과도기에 겪어서 모르겠지만, 지금은 이미 어느정도 자리잡아서 메타버스에서 실험하기도 하고, AI 초등학교때부터 배우고 있다. 가상환경 체험으로 학교에서 개편되어있다. 수업도 다 가상공간에서 하고있다. 제페토 많이 한다. 명품매장들도 많이 들어와있다.
메타공간 안죽었다. 소비자가 바뀌고 있다. 엘지에서도 메타공간에서의 소비자에 대해서 고민하겠다고 정책 방향을 바꾸고 있다. 소비자층이 올라오고 있다. 메타공간의 장점은 데이터가 실시간으로 쌓인다. 동선이나 데이터들이 다 쌓인다. 데이터를 어떻게 수집할 것인지를 심각하게 고민해야한다. 소비자들에게 재미를 주면서 어떤 가치있는 데이터를 가져올지에 대한 고민을 해야한다. 데이터 수집 시 고려해야할 부분 중 하나가 단어에 대한 제한요소를 거는 것이다. 개인정보 수집 시 보안정책에 대한 부분도 항상 잘 봐야한다.
K-means Clustering

가운데 점을 잘 찍나 확인하는 것이다. 랜덤하게 데이터를 50개 만들고 다 2를 더한다. 그리고 또 다른 랜덤한 데이터를 만들고 행마다 6을 더했다. 랜덤하게 만든 데이터임에도 불구하고 행과 열을 떨어뜨려놔서 2를 더한 점과 6을 더한 점 그룹이 각각 분리되어 있는지 본다.

아래 머신러닝용이다.

클러스터개수가 몇개로 할 것인지 찾는 것을 엘보기법이라고 한다. 몇 개를 했을 때 가장 최적화될 것인지를 본다.
Kmeans 알고리즘을 불러와서 그 데이터를 피팅하고, 각 데이터 포인트가 속하는 군집의 labels을 만들고, 중심점 좌표를 찾는다.

별은 위치값의 중심점이다.
중심점을 계산하는 원리를 이해하는 것이 중요하다. K-means에서 가장 중요한 것은 클러스터의 개수를 결정하는 것이다. 두 개의 클러스터로 나누었을 때가 가장 적합한지, 세 개로 나누었을 때가 더 효과적인지를 분석해야 한다. → 비지도 학습
비지도 학습은 Y값(정답 레이블)을 제공하지 않고, 데이터의 패턴이나 구조를 스스로 찾아내는 방식이다. 반면, Y값이 주어진 상태에서 X값과 Y값 간의 연관성을 학습하는 것은 지도 학습이라고 한다.
💡 비지도 학습 (Unsupervised Learning)
Y값(정답 레이블)이 제공되지 않습니다. 데이터가 어떤 패턴이나 구조를 가지고 있는지, 데이터를 그룹화하거나 숨겨진 관계를 찾는 데 초점이 맞춰져 있습니다.
예시:
클러스터링(Clustering): K-means, DBSCAN, 계층적 클러스터링 등
차원 축소(Dimensionality Reduction): PCA, t-SNE 등
💡 지도 학습 (Supervised Learning)
Y값(정답 레이블)이 주어져 있습니다. 주어진 X값(입력 변수)과 Y값(타깃 값) 간의 관계를 학습하여 새로운 데이터에 대해 예측을 수행합니다.
예시:
분류(Classification): 로지스틱 회귀, SVM, 신경망 등
회귀(Regression): 선형 회귀, 랜덤 포레스트 회귀 등
만약에 제페토에서 가입한 날짜, 성별, 돌아다닌 시간, 움직이지 않은 시간을 확인하고 나서 고객이 이번에 구매를 한 것 같아?를 Y or N를 할 수도 있고, 물건 구매를 한 사람의 데이터를 보고 다음달 매출을 예상하는 것이 있다. 예측하거나 분류할 때 쓰는 것은 Y값을 줘야 하고, 비지도 학습은 클러스터링할 때 많이 쓰인다.


정규분포는 데이터의 극단치를 제외한 나머지 부분을 데이터의 분포도가 히스트로그램이 비슷한 분포도에 이루어져있기 때문에 분석할 가치가 있는지 확인한다. 정규분포화가 되어있다. 빅데이터에서는 정규분포 유무에 신경을 안쓴다. 통계학적으로 갈지, 머신러닝으로 갈지 차이점은 머신러닝은 미래데이터에 대한 예측이고, 숫자하나를 예측하거나 분류한다고 명확하게 나눠주는 것이고, 통계들은 고전적인 통계로 기존의 자료의 정확성을 확인한다. 자료가 얼마나 정확한 자료인지 확인한다. 통계쪽은 확인하는 용도이다. 머신러닝을 하기 위해 통계를 봤던 것이고, 두개를 쓰는 사람이 다르다 보니까 두가지를 적절히 잘 사용해야하는 것이다.

아래쪽 Feature1 나이, Feature2 접속횟수라고 가정했을 시, 네개의 그룹을 마케팅 방안을 다르게 짤 수 있다. 연령대는 낮고 접속횟수는 높은 사람/연령대는 높고 접속횟수는 높은사람.. 나눌 수 있다.
GPT로 인사이트를 얻는다.

통계하는 쪽에서 아주 고전적인 통계학적 기법이기 때문에 근거로 삼으면 할말이 없다. 고객 연령층을 3개로 해도 된다면 클러스트를 3개만 두고 해도 된다. 클러스터링 연두, 초록색은 나이는 많고 추가적 맞춤형 혜택을 할 수 있다고 도출할 수 있다.
챗봇 어시스턴트는 클러스트 몇개로 한다고 하면 그래프 까지만 보여주고 별표 계산은 우리가 해야했지만 이제는 챗봇이 별표도 계산해주고, 비즈니스 인사이트까지 도출해준다. 데이터 드롭만 하면 이정도의 인사이트가 나온다. BI 관련 프로그램들은 돈을 내면 이거를 회사 맞춤형으로 만들어준다. 그런데 아직은 막 그런때가 아니지만, 우리만의 강점이라고 하면 클러스터링 할 수 있다~라는 건 경영과에서 기본적으로 하는 말이다. 파이썬 할 수 있다~라는 것도 기본적으로 하는 말이다. 보고서 쓰는데 속도를 높일 수 있어요~하는 것도 우리가 말할 수 있는 강점이다.

유클리드 거리 계산. 이런과정을 한번 하는게 아니라 계속적으로 한다는 이야기이다. 이거에 대한 수학공식이 이해가 안된다면 이 자료를 넣고, K값을 주면, 임의의 장소에다가 넣어줄거다.

공식적인 다큐멘터리/도움말을 확인해봐야한다.



https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.xlim.html
matplotlib.pyplot.xlim — Matplotlib 3.10.0 documentation
Get or set the x limits of the current Axes. Call signatures: left, right = xlim() # return the current xlim xlim((left, right)) # set the xlim to left, right xlim(left, right) # set the xlim to left, right If you do not specify args, you can pass left or
matplotlib.org

맨 처음에 초기값을 넣을 때 무작위로 랜덤하게 뿌릴건지, 공식에 의해 뿌릴건지 정한다.
원칙적으로는 여기에 나와있는걸 보고 사용을 해야한다. 하지만 여기에 나온 공식들을 막 그렇게 사용하지는 않는다. 옵션값들에 대한 부분을 조정하지 않아도 데이터들이 되는 케이스들이 많고, 공식으로 이미 들어와있기 때문에 공식에 문제가 있으면 찾아볼수는 있으나, 다 보기에는 정말 힘들다.

K-means에서 군집을 몇 개로 하는게 좋을지 정하는 것이다.

군집개수별로 나온다. 7개정도 하면 좋겠지만 그림을 출력해보고 나서 7개씩이나 할필요 없을 것 같은데 라고 한다면 scatter 그래프를 보고 임의로 정할 수도 있다.

책 예제 공부할 때는 아무 문제가 안생기지만, 혼자 사이킷런 돌릴때 형태때문에 엄청 고생한다. shape값을 바꾸라는 에러가 엄청 많이 뜬다.



fit하고 안하고의 따라서 계산이 들어가는지, 안들어가는지 정규화 부분에서 중요한 이슈가 생성된다.

flatten은 reshape 명령어이다. reshape(-1) 의미는 1차원으로 만들자.
kmeans나 사이킷런은 2차원으로 계산하고, 최종적인 분야는 1차원으로 들어가야 이걸로 차트로 그리고, 클러스트1만 뿌리고, 클러스트2만 뿌릴 수 있어서 그렇다.
flatten은 1차원으로 만드는 명령어라고 생각하면 된다. 인공지능 들어가면 맨 마지막에는 무조건 1차원으로 데이터를 만들어야 한다.
군집 내 데이터 간의 응집력과 군집 간의 분리도를 평가한다.
응집력을 계산한다.

거리값이 가장 적은 지점이 몇번인지 본다. silhouette_score가 뭔지 알아야 한다.
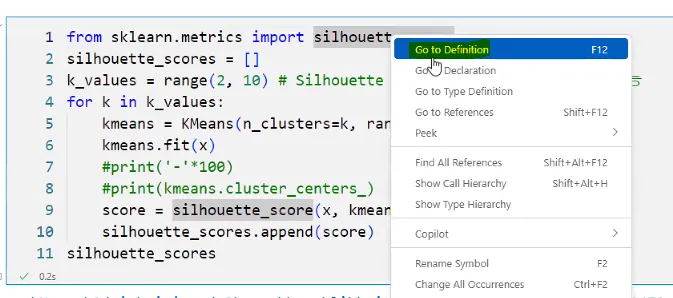
이렇게 들어가면 함수의 정의를 볼 수 있다. 해석한다면 클러스터1에 해당하는 거리차랑 제곱을 해서 구한다. x값 넣고 라벨값 넣어서 체크 X,Y들어가는 함수를 구하라는 것이다. 이 안에는 굉장히 많은 수학 공식이 적용이 되면서 값이 리턴되는 함수들이다.
💡 머신러닝 추정기(estimator)
주어진 데이터를 기반으로 특정 값을 예측하거나 모델을 학습하는 객체를 의미한다. 주로 Scikit-learn 라이브러리에서 사용되는 개념으로, 추정기는 머신러닝 알고리즘을 구현한 클래스를 가리킨다. 추정기를 사용하면 데이터를 학습(fit)하고, 예측(predict)하거나, 확률을 추정하거나(transform)하는 등의 작업을 할 수 있다. 추정기는 머신러닝 워크플로우에서 핵심 역할을 하며, 데이터를 처리하고 모델을 학습시키는 전 과정을 효율적으로 관리할 수 있도록 도와준다. Scikit-learn 라이브러리를 사용하면 다양한 추정기를 쉽게 활용할 수 있다. 추정기 버전이랑 일반 버전이 다르다. 수학 공식을 갖고 있는 모듈이다.
💡 실루엣 계수(silhouette_score)
좋은 군집화란 클러스터링 기준으로 잘 뭉쳐있는 것(응집도가 좋은 것)이다. 차이의 합이 작을 것이다.




숫자데이터만 있는 경우엔 이거를 안해도 되지만, A,B,C라는 값을 숫자로 바꿔줘야하는 것을 라벨을 붙여주는 인코딩 방법이다. 이름만 갖고서는 순서에 의미를 갖고 있지 않다. 순서의 의미가 없으면 라벨링을 하면 된다. 라벨 인코딩의 문제는 숫자가 크면 y라는 예측값을 구하는데 있어서 y값이 커지면서 예측값 차이가 커진다. 문자 자료가 숫자로 바뀌면서 C보다 A가 점수가 높아야하는게 아니라면 라벨링 코딩은 하지 말아야 한다. 이때는 원-핫 인코딩을 한다.

중복을 바꿔주고, unique하게 만들어준다. ‘사과’를 0번이라고 하고, ‘바나나’를 1번이라고 하고, ‘딸기’를 2번이라고 한다. fit이 이런 과정이다. fruits를 [0,1,2,1,0]이라고 바꿔주는게 transform이라고 한다. 라벨 인코딩은 되는 케이스가 있고, 안되는 케이스가 있다.


판매데이터라고 했을 시, 20명 정도가 산 물건을 교차로 하면 교차 안되는게 훨씬 많다. 그래서 데이터값이 0이 너무 많아져서 희소행렬이 만들어진다. 차원의 저주라고 불린다. 쓸데없이 빈공간만 넘쳐난다는 뜻이다.
카테고리가 너무 많을 때는? 지역은 57개이고, 상품의 카테고리가 3000개라고 할때, 이 모든 것을 원-핫 인코딩 할 수 없다. 실제 데이터보다 0값인 희소행렬이 많이 발생한다.
다음 수업에는 차원 축소를 배울 예정이다. 숫자를 만드는 과정을 채택했구나 정도를 알면 된다. 직접 코딩을 할 필요는 없다. 우리 포지션은.
정규화
머신러닝 돌릴 때 기본으로 돌리는 정규화. 정규화를 하지 않아도 되는 것들은 랜덤 포레스트들은 정규화하지 않아야 한다.
이 작업 할때 첫번째 변수는 나이, 두번째 변수는 급여라고 할때, 급여는 천/억이라고 할때 중심점을 잡았는데 급여데이터는 억원이고, 나이는 0에서 100인 것이다. 이 두 차이의 갭차이가 크다. 그래서 특히 클러스터링할 때 중간점 찾기가 너무 거리가 멀다. 처음부터 값이 엄청 떨어져있어서 계산하기가 이상했다. 그래서 값을 일정한 사이즈로 줄이는 것을 정규화라고 한다.
우리의 모든 작업의 기본은 값을 좌표상에 뿌려놓고, 너랑 나랑 가깝니?를 보는 것이다. 정규화 기법을 통하지 않으면 벡터를 한자리에 모아둘 수가 없다. 회귀분석을 할 때, 서울이 1, 제주가 57이라서 y값에 영향을 많이 미치는 것처럼, 어떤 판매액때문에 age에 영향을 크게 미친다. 나이값이 영향이 약해지는 상황이 벌어진다. 만약 판매 금액을 예측하고 싶을 때, 나이, 판매금액으로 볼때, 모든 자료를 일정한 값 사이에 가둬놓고, 비슷한 값으로 이해할 수 있게 해줘서, y값에 영향력을 똑같이 주려고 하는 것을 정규화방법론이라고 한다.
정규화 부분이 들어가는 작업을 하게 되면, 어떤건 피팅하고 어떤건 트랜스폼하고 뒤죽박죽 될 수 있다. 해도 의미가 없는 것은 안하는 게 맞다.

원핫인코딩은 min-max 정규화를 안돌려도 된다. 값이 똑같이 나온다.

캐글 고객 세분화, 전자상거래 데이터 분석, 온라인 소매 고객 세분화 예제 보기
https://www.kaggle.com/code/blanik/kor-e-commerce-data-3-customer-segmentation
[KOR] E-Commerce Data: 3. Customer Segmentation
Explore and run machine learning code with Kaggle Notebooks | Using data from E-Commerce Data
www.kaggle.com
코드가 결국에는 다 거기서 거기인데 보기 편한걸로 찾아주신다 함.
import 코드에 이상한 불필요한 사이킷런 많으면 안봐도된다.
추가로 개인 프로젝트할 때, 이커머스나 물류 데이터를 가지고 와서, 수학적 알고리즘을 알고 있다는 것을 증명하면 된다.

포트폴리오에는 나 왜 뽑아야 하는지 쓰는 거다. 나 이렇게 잘한다고 보여주는거다. 프로젝트 할때마다 1장짜리 작업해라.
다른사람보다 기획도 할 수 있는데, 랭체인 기반 설계, API 이용할 수 있다를 기술해 놓아야 한다.
통계 분석 내용도 들어가야 한다.
- 고객 클러스터링 및 챗봇 어시스턴트 개발
(목표, 주요 내용)
파이썬 머신러닝을 활용한 비정상 거래피턴 식별 이렇게 자세하게 써야한다. 그래야 제목만 보고서도 파이썬 머신러닝도 다 했다는 것을 알려줘야 한다.
- OpenAI GPT 모델 기반 질문응답 및 학습 추천 기능 설계
이렇게 제목은 자세하게 길게 들어가야 좋다. 아니면 서브제목을 쓰던지해서 어떤 기술을 썼는지 알려줘야 한다. 읽는 사람들은 짧은 시간안에 읽어야 해서 밑 내용을 잘 안읽는다. 제목 중요하다.
데이터분석과 AI기획을 접목한 프로젝트 다수
'데이터 AI 인사이트 👩🏻💻 > KPMG 교육' 카테고리의 다른 글
| 비즈니스 애널리틱스 II (4) PCA와 차원축소, AutoML, 데이터스케일링, Fit & Transform (0) | 2025.02.10 |
|---|---|
| 비즈니스 애널리틱스 II (3) K-means, 유사도 계산, 단위 벡터 (0) | 2025.02.10 |
| 비즈니스 애널리틱스 II (1) 랭체인, 판다스 AI 보고서 작성, 생성형 BI, Numpy (0) | 2025.01.26 |
| 비즈니스 애널리틱스 I (3) 텍스트 분할 & 임베딩, 벡터 유사도 분석, 형태소 분석, 네이버 쇼핑몰 데이터 RAG (1) | 2025.01.26 |
| 비즈니스 애널리틱스 I (2) 네이버 API 활용을 통한 데이터 수집, 전처리, 분석, 시각화 (0) | 2025.01.26 |



