SPSS/SASS 통계 소프트웨어
spss에서 세그멘테이션, RFM, kmeans 할 수 있다.
spss는 통계전문 소프트웨어 / 드래그앤드롭만 해도 해준다. / 시각화가 안되서 별도의 툴로 해야한다.
RFM 분석 : 접근 빈도성으로 고객을 분류해주는 방법론
통계만 전문적으로 하는 리서치 회사들한테 별거 아닌데도 외주로 줄만큼 회사 내부에서는 분석관련한 작업을 거의 하지 않는다. 분석안하고 판매 집계 작업만 한다. 심도 있는 분석인 회사에서 하지 않는다.
이제는 SPSS나 SASS 처럼 비용을 내지 않는 파이썬으로 작업이 가능하다는 것이다. 기술반이면 오늘 벡터나 넘파이 (한달내내한다), 리스트 얘기하고 있을거다. 넘파이를 정확히 알고 있는지 질문공세를 엄청한다. 아무리 포트폴리오를 해놨다고 해도 신뢰가 백프로 안되기 때문에 기술영역 질문을 엄청 한다. 데이터 분석 직무는 왜 이런 현상이 일어나는지 명확히 알고 있는지를 물어보는 전반적인 상황을 이해하는지를 물어본다. 큰 회사들은 기술면접보는 사람도 들어올 수 있다. 경영학적 부분에서 데이터 분석이 굉장히 잘되고 있었던 통계분석작업을 외주를 줄 의향이 있는데, 당신을 뽑아야할 이유가 뭐냐고 어필해보라고 할 것이다. 기존 통계 외주 회사의 단점을 알아야 한다. 비용도 문제이지만 가장 큰 문제는 실시간 들어오는 데이터를 처리하지 못한다는 것이 가장 큰 문제다. 수 많은 시스템은 연구소와 프로그래머들이 만들어내는 시간이 꽤 있고, 직속연구소가 아닌 이상은 우리 데이터만 보는 것도 아니고, 데이터는 실시간으로 바뀌고, 세상은 빠르게 변한다. 커머스가 아닌 물류만 하더라도 도로교통상황은 실시간으로 바뀐다. 예전에는 소비자들이 이해를 해주었지만, 이제는 소비자들이 기다려주지 않는다. 신선제품들은 빠르게 배송을 해야하는 것도 있고, 날씨상황을 이해해주지 않는 소비자들이 많다. 그래서 이에 대한 대응을 실시간으로 해야하지만, 이제는 실시간으로 생성되는 데이터량을 외주에 맡기는것이 효과적이지 않다.
인공지능쪽은 아주 뛰어난 연구소나 학교에 맡겨버리는 경우가 많다. 회사 직원들은 핸들링만 하는 경우가 많다. 외부랑 연결하는 케이스들이 많다.
SPSS나 SASS ‘커널’이라는 게 있다. 회사는 어느정도 데이터들을 처리할 수 있는 GUI기반 인터페이스 기반들이 다 있다. 버튼만 누르면 결과가 나오는 것들이 들어가 있어서, 굳이 내가 소프트웨어를 몰라도 쓸 수 있다.
kmeans 정규화 방법
비지도 학습: 데이터를 꾸려놓고 알아서 해라는 것이다.
지도 학습: x데이터를 주고, y데이터를 준 다음에 x데이터 y데이터 간의 관계를 계산하는 것이다.
→ y값을 안주면 비지도 학습, 주면 지도 학습
노량진에서 붕어빵을 하나 체인을 하려고 한다. 위치를 선점해야하는데 붕어빵이라는 특성이 저렴하고 간단하게 먹을 수 있고 집근처에 있어야 한다는 입지조건이 있는데 지점의 위치를 어느 중심에 넣는 것이 좋은지 물어보는 것을 k-means 로 사용할 수 있다.
장점: 빠르고 쉽다.
단점: 초기 중심점 선택에 따라 결과가 달라질 수 있다.

데이터가 2,5,7,1 이렇게 있는데 300이 있으면 중심점 위치가 이상한 식으로 반복하게 될 수 있다. kmeans할때 가장 중요한 것은 데이터를 같은 범위로 줄어줘야한다 → 정규화/표준화
알고리즘 특성상 단점이 존재한다. 선형일때는 괜찮은데 비선형일 때 문제가 생긴다.
데이터 x값이 2면, y값도 2이다. x가 4이면 y가 4다. 데이터를 아무리 뿌려도 직선으로 보여진다.

고객 금액에 따른 유도는 필요없지만, 문구에 대한 것은 나이대에 달라서 마케팅을 다르게 수립해야겠다고 하면 그대로 하면 되지만,

kmeans는 데이터를 통계적으로 풀어주지만, 시각화를 보고 우리가 다시 해석해야하는 것도 있다.
→ 지역 최소화 (Local Minimum)
인공신경망 들어가면 지역 최소화에 걸려서 아무것도 못할 때도 있다.

https://blog.naver.com/bestinall/223471475671
유저 세그먼트 설계를 위한 K-Means 클러스터링(Clustering)
데이터 분석 방법론 - 유저 세그먼트 설계를 위한 K-Means Clustering 안녕하세요, 데이터 마케팅 공부...
blog.naver.com
유사도 계산


리스트와 어레이 구조에서 굳이 고생하지 않더라도 사용할 수 있게끔 함수를 제공하는 프로그램을 사용해서 작업할 수 있다.
헹렬을 알아야 하는 케이스가 추천시스템이다.

자세히 알려면 행렬 기호같은 것도 알아두면 좋겠다.


데이터사이언티스트는 안뽑아준다. 통계과, 수학과를 베이스로 한 과만 뽑아준다. 이거 잘쓰는 알고리즘알고있고, 구현가능하다는 것을 만들어내야한다. 그런데 서류에서 통과가 안된다. 우리는 데이터사이언티스트들을 석박사 이상만 뽑는다.
프로그래밍쪽으로 밀고나가든, 통계쪽을 안다는 것을 증명해야한다.
분석가와 사이언티스트 접점이 많고, 경계가 불분명하기 때문에 분석가로 시작해서 접해보면 된다.
사이언티스트는 통계적 모델링하는 사람들이다.
분석가들은 인사이트를 뽑는 것이 더 중요하다.
단위 벡터
아래 질문처럼 GPT에 물어보기.



데이터에 x변수가 너무 많으면 x변수를 묶어야한다. 단위벡터화하는 정규화하면 된다.
문장이나 텍스트가 들어가 있는 것은 클러스터링 하기 전에 데이터를 숫자화하는 방법론을 해야한다.
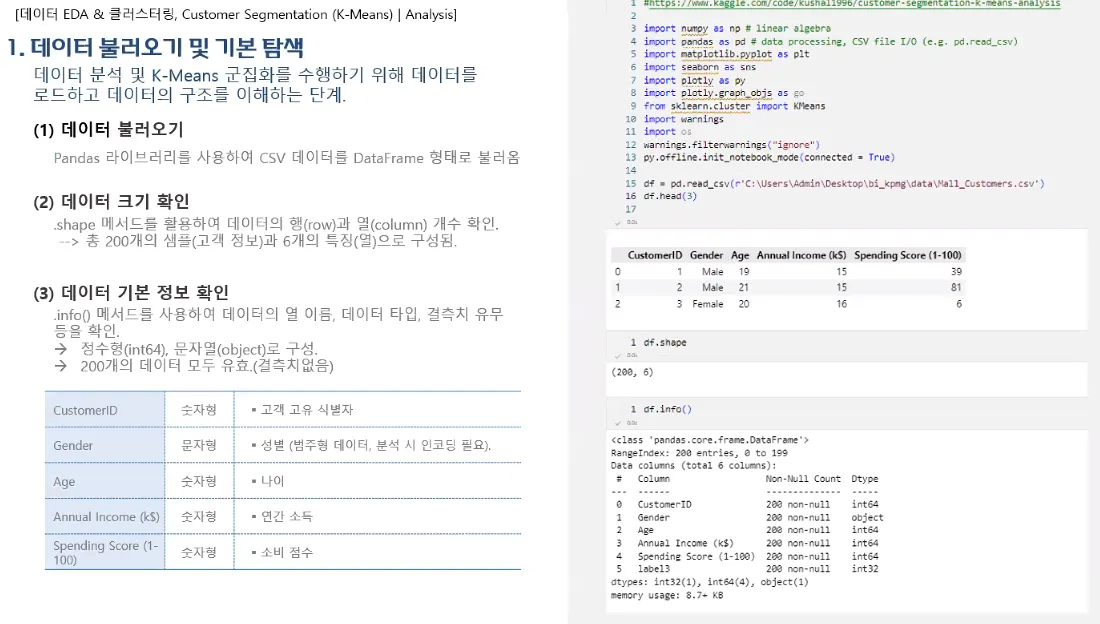

이거 잘 나오는 이유는 이 데이터가 캐글출처이고, 데이터 양이 적기 때문이다. 새로운 데이터를 넣고, 방대한 양이라면 GPT가 잘 못한다.
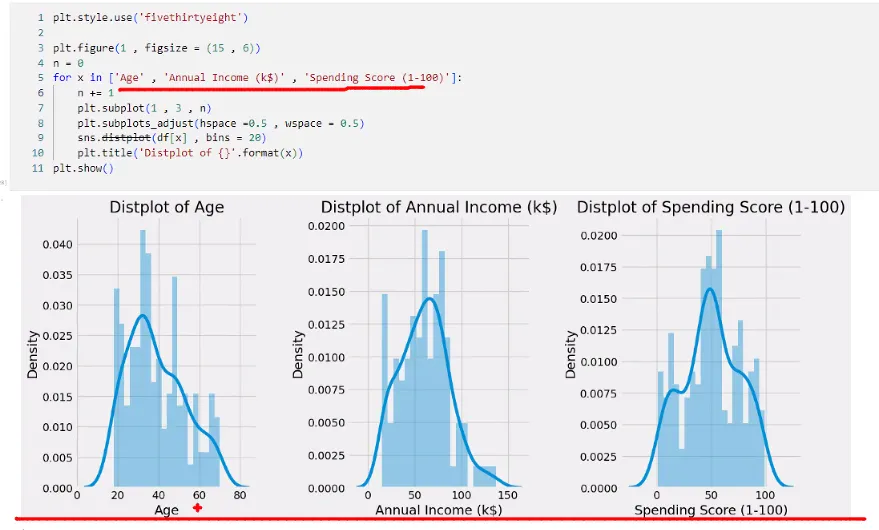
숫자데이터들을 먼저 이상치가 있는지, 왜도와 첨도를 눈으로 확인한다. 표준화하려고 하는 작업이다. 위 자료는 스칼라 작업을 할 필요가 없어 보인다.
데이터 편향 여부도 확인해야한다. 남자 여자 데이터 골고루 있는지

산점도를 보면 직선일수록 상관있는 것이다.

상관이 없어서 가로로 한줄로 보이는 것을 비선형이라고 한다. init = k-means를 쓰면 된다. 그룹화해서 나눠서 뿔뿔이 뿌린다음에 평균점을 이동해서 본다. 지역최소화라는 이상현상에 빠질수가 있다.

그룹이 눈으로 보인다.


위 분석은 RFM 분석해서 4개의 세그멘테이션(고객군)했다는 것이다.

우리가 그룹제목 내용처럼 인사이트를 주는 것이다. 개인화된 추천도 있지만 추천자체가 달라진다.
페르소나를 만들더라도 젊은 소비자에 맞춘 것, 활동적인 젊은 소비자에 맞춘 것이 다 다르다. 이렇게 나누면 효과적인 마케팅을 할 수 있다.
'데이터 AI 인사이트 👩🏻💻 > KPMG 교육' 카테고리의 다른 글
| 비즈니스 애널리틱스 II (5) 분산, 공분산, PCA, 추천시스템 (0) | 2025.02.10 |
|---|---|
| 비즈니스 애널리틱스 II (4) PCA와 차원축소, AutoML, 데이터스케일링, Fit & Transform (0) | 2025.02.10 |
| 비즈니스 애널리틱스 II (2) 넘파이, 군집분석(K-means), 클러스터링 (0) | 2025.02.10 |
| 비즈니스 애널리틱스 II (1) 랭체인, 판다스 AI 보고서 작성, 생성형 BI, Numpy (0) | 2025.01.26 |
| 비즈니스 애널리틱스 I (3) 텍스트 분할 & 임베딩, 벡터 유사도 분석, 형태소 분석, 네이버 쇼핑몰 데이터 RAG (1) | 2025.01.26 |



